Arafed Futures
Leon-Etienne Kühr, Multi-Media Installation / Custom Software, 2025 (Diplom 2)
„Arafed Futures“ ist ein experimentelles Forschungsprojekt, das generative Systeme der künstlichen Intelligenz über Code erforscht. Während generative KI uns oft als monolithische Blackboxen hinter Chatbot-Schnittstellen erscheint, offenbart die Entfernung dieser obersten Ebene und die direkte Interaktion mit den zugrunde liegenden Modellen über deren programmierbare Schnittstellen ein komplexes Netz unterschiedlicher Modelle, die in durchdachten Pipelines zusammenwirken. Genau dieser Prozess des Pipelinings treibt die aktuelle Welle der KI an, die in weiten Teilen das Ergebnis rigoroser ingenieurtechnischer Bemühungen ist. Doch genau dieses programmatische Ineinandergreifen von Modellen unterschiedlicher Herkunft und Modalität führt auch zu einer immer weiter wachsenden Unvorhersehbarkeit: jenseits einer fundierten Vermutung ist es unmöglich, die Ergebnisse eines Systems vorherzusagen.
Angelehnt an Stafford Beers Prinzip „Der Zweck eines Systems liegt in dem, was es tut“ beschränkt sich unser Verständnis auf den Inferenzprozess, also darauf, mit dem System zu interagieren und die Modelle auszuführen. Die Interpretation der Ergebnisse wird zudem durch das Design erschwert: Die Ausgaben sind zwar in Menschen lesbar, aber nur implizit, geprägt durch trainingsbedingte Daten menschlichen Ursprungs. Texte und insbesondere von KI erzeugte Bilder werden zur Projektionsfläche für unsere begrenzte Auffassung dieser Systeme. Dennoch lässt sich generative KI dekonstruieren: sie kann zerlegt, umorganisiert und wieder zusammengesetzt werden. Dabei entwirren wir nicht nur algorithmische Feinheiten, sondern legen auch eingebettete Verzerrungen und häufig reduktionistische Funktionsweisen offen.
Bilder und Sprache sind Teil einer Reihe von Kompressionstechniken, die alle sorgfältig darauf ausgelegt sind, am Rand der menschlichen Wahrnehmung zu operieren. Im Fall von Text liegt dieser Rand irgendwo zwischen formelhafter Werbesprache und reinem Wortsalat. Die Gestaltung dieser Möglichkeitsräume ist nicht nur ein mathematischer Prozess, sondern auch ein politischer: Durch Datenaufbereitung, -augmentation, -filterung und gezielte Trainingsinterventionen lässt sich der Spielraum der KI-Generierung subtil und implizit verändern, was in großen KI-Unternehmen zum Standard gehört.
Die folgenden Experimente untersuchen die Ränder des Chaos, die zugrunde liegenden Möglichkeitsräume und die Konsequenzen dieser verflochtenen Pipelines.
“Arafed Futures” is an experimental research project exploring generative artificial intelligence systems through code. While generative AI often appears to us as monolithic black boxes hidden behind chatbot interfaces, stripping away this top layer to interact directly with underlying models via their programmable interfaces reveals a complex web of different models interacting in deliberate pipelines. It is this process of pipelining that fuels the current wave of AI, largely the result of rigorous engineering efforts. Yet this programmatic entanglement between models of differing origin and modality also drives ever-increasing unpredictability: beyond an informed guess, predicting a system’s outcomes is impossible.
Akin to Stafford Beer’s principle, “The purpose of a system is what it does,” our understanding becomes limited to the process of inference, interacting with the system and running the models. Interpreting the results is further complicated by design: outputs are human-readable but only implicitly so, shaped by human-origin training data. Texts, and especially images, generated by AI become surfaces onto which we project our limited understanding of these systems. Still, generative AI can be unengineered: taken apart, reorganized, and reassembled. In doing so, we unravel not only algorithmic intricacies but also embedded biases and often reductionist modes of functioning.
Images and language are part of a series of compression techniques, all carefully designed to operate at the border of human perception. For text, this border lies somewhere between formulaic advertising copy and pure word salad. Shaping these possibility spaces is not only a mathematical process but a political one: through data preparation, augmentation, filtering, and deliberate training interventions, the range of AI-generated outcomes can be subtly, and implicitly, altered, a standard practice in large AI firms. The following experiments investigate the edges of chaos, the underlying possibility spaces, and the consequences of these interlaced pipelines.
Systems in Homeostasis
Systems in Homeostasis
Wenn wir mit generativen KI-Systemen interagieren, insbesondere mit solchen, die auf Eingabeaufforderungen angewiesen sind, ist die vermeintliche Eins-zu-eins-Beziehung zwischen Eingabe und Ausgabe oft trügerisch. Trotz Bezeichnungen für Modellarchitekturen wie „Text-zu-Bild“ oder „Bild-zu-Bild“ ist das, was wir phänomenologisch beim Prompten beobachten, ein probabilistischer Prozess, der davon geprägt ist, wie das System die Eingabe nutzt, um einen stochastischen Prozess auf der Grundlage gleichmäßig verteilter Rauschmuster zu steuern. Gemäß Stafford Beers Diktum „Der Zweck eines Systems ist das, was es tut“ können wir den zugrundeliegenden Möglichkeitsraum und die Art und Weise, wie unsere Souffleure ihn durchqueren, nur durch die Verwendung dieser Systeme verstehen. Dies wird durch unsere ständige Bereitschaft behindert, uns von jedem neuen Artefakt, sei es visuell, semantisch oder rechnerisch, täuschen zu lassen, und durch unsere Unfähigkeit, sie nicht als eine sinnvolle Interpretation unserer Eingaben zu verstehen. Eine Strategie, um dieser Dynamik zu begegnen, ist das „Non-Prompting“: Indem wir unsere gezielten Eingaben zurückhalten und ein System sich selbst überlassen, können wir die intrinsischen Verzerrungen der KI beobachten, die sich als ‚mittlere‘ oder „durchschnittliche“ Konzepte (generische Gesichter, Landschaften und Bildmaterial) manifestieren, die den meisten generativen Modellen zugrunde liegen.
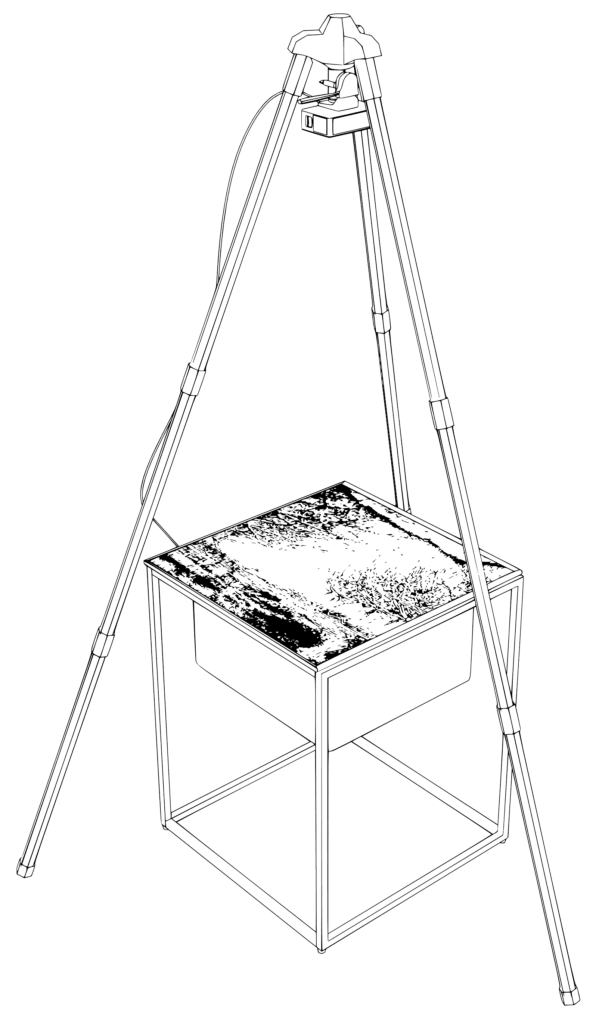
In Systems in Homeostasis filmt eine Kamera einen Bildschirm, auf dem eine KI-verarbeitete Echtzeit-Einspeisung der von ihr aufgenommenen Bilder zu sehen ist. Mit jedem neuen Bild, das in das Modell einfließt, konzentriert sich die Rückkopplungsschleife auf vertraute Standardmotive: Gesichter, Tiere und Werbefragmente. Gelegentliche Unterbrechungen durch den Menschen, wie z. B. die Unterbrechung der direkten Sichtlinie, stören vorübergehend die Homöostase des Systems, das jedoch bald wieder in denselben Standardzuständen auftaucht. Dieses kontinuierliche „Defaulting“ offenbart nicht nur den zugrundeliegenden systemischen Reduktionismus, sondern verstärkt auch die Normativität innerhalb des Modells: Die Menschen erscheinen überwiegend weiß, mittleren Alters und tragen Anzüge, während die Innenräume als sauber und künstlich dargestellt werden. Wenn es sich selbst überlassen wird, bleibt das rekursive System nicht nur in konzeptuellen Senken gefangen, sondern schlängelt sich auch endlos durch nahezu identische Bilder, was darauf hindeutet, dass alle Bildmodelle bereits in sich zusammenfallen könnten.
When we interact with generative AI systems, particularly those reliant on prompting, the presumed one-to-one relationship between input and output is often deceptive. Despite labels for model-architectures like “text-to-image” or “image-to-image,” what we phenomenologically observe while prompting is a probabilistic process shaped by how the system uses the input to guide a stochastic process based on uniformly distributed noise patterns. In line with Stafford Beer’s dictum “The Purpose of a System is What it does”, our only means of understanding the underlying possibility-space and how our prompts traverse it, is through using these systems. This is obstructed by our continuous willingness to be deceived by each new artifact, be it visual, semantic, or computational and our inability to not interpret them as a meaningful interpretation of our input. A strategy to confront this dynamic is “Non-Prompting”: by withholding our directed inputs and leaving a system to its own devices, we can observe the AI’s intrinsic biases, which manifest as the “mean” or “average” concepts (generic faces, landscapes, and stock imagery) that underlie most generative models.
In Systems in Homeostasis, a camera films a screen displaying a real-time, AI-processed feed of its own captured images. As each new frame re-enters the model, the feedback loop converges on familiar default motifs: faces, animals, and fragments of advertisements. Occasional human interruptions, such as breaking the direct line of sight, temporarily disrupt the system’s homeostasis, but it soon re-emerges in the same default states. This continuous “defaulting” not only reveals the underlying systemic reductionism but also enforces normativity within the model: people appear predominantly white, middle-aged, and wearing suits, while interiors are presented as clean and artificial. When left on its own, the recursive system not only becomes trapped in conceptual sinks but also meanders endlessly through near-identical imagery, hinting that all image-models might already be collapsed as they are.


Arafed
Arafed
Generative künstliche Intelligenz hat die Geschichte in ein Vorher und ein Nachher geteilt. Seit dem Aufkommen von Textgeneratoren wie ChatGPT und Bildgeneratoren wie Stable Diffusion stehen unsere gemeinsamen digitalen Artefakte unter dem ständigen Verdacht, von künstlicher Intelligenz generiert zu sein. Diese Welle von Systemen der künstlichen Intelligenz wird durch das angetrieben, was als „natürliche Sprache“ bezeichnet wird, d. h. die Untergruppe der Wortkombinationen, die als Teil der menschlichen Sprache und des Textes gelten. Doch dieses implizite Sprachverständnis ist trügerisch: Unter der ersten Schicht der Benutzeroberfläche verbirgt sich eine Maschinerie aus beweglichen Teilen und Algorithmen, die die natürliche Sprache in Symbolbrocken umwandelt. Diese Symbole, Token genannt, dienen der Kommunikation mit trainierten tiefen neuronalen Netzen und fungieren als Quasi-Protokollschicht. Das Token-Vokabular selbst wird durch Methoden generiert, die von Komprimierungsalgorithmen inspiriert sind. Das Ergebnis sind einige Token, die direkt Wörter darstellen, und andere, bei denen es sich lediglich um eine Reihe von Sonderzeichen oder Codes, aber auch um Markennamen und Hashtags handelt, da der Ursprung dieser Maschinensprache Texte sind, die akribisch aus dem Internet gecrawlt wurden. Jedes Token wird durch eine ganzzahlige ID dargestellt, die mit 0 beginnt und mit einer festen Zahl endet, die die Länge des Vokabulars darstellt und in der Regel zwischen 50000 und 150000 liegt.
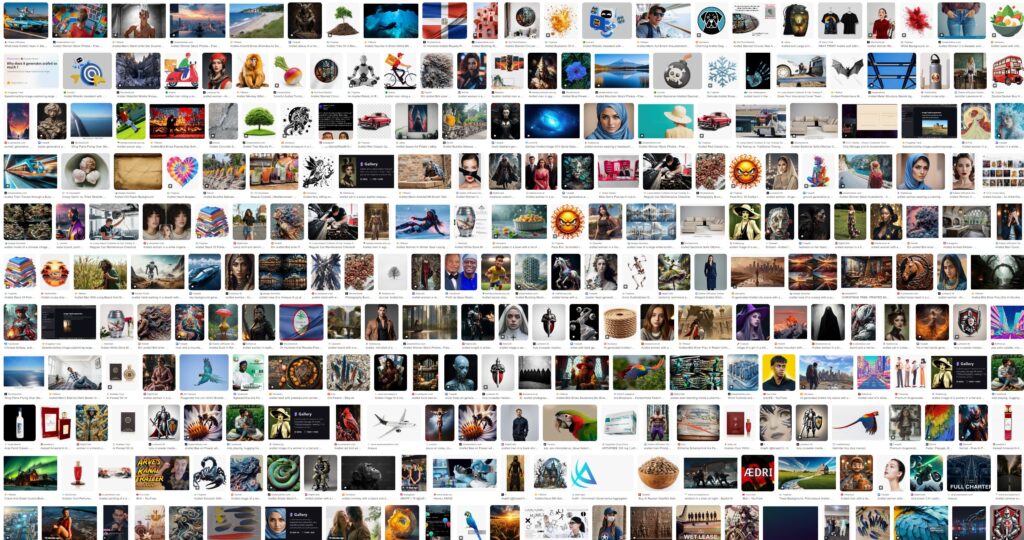
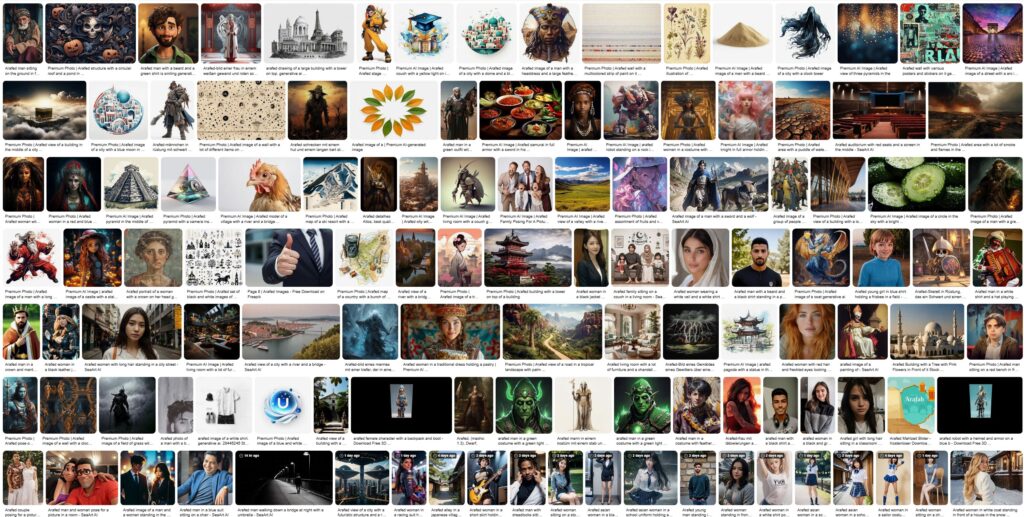
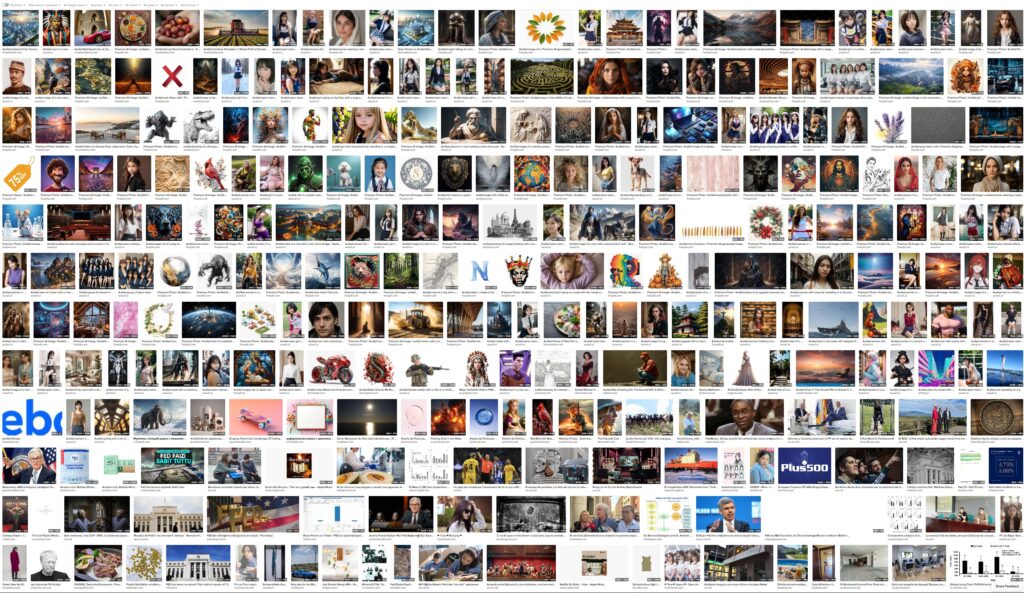
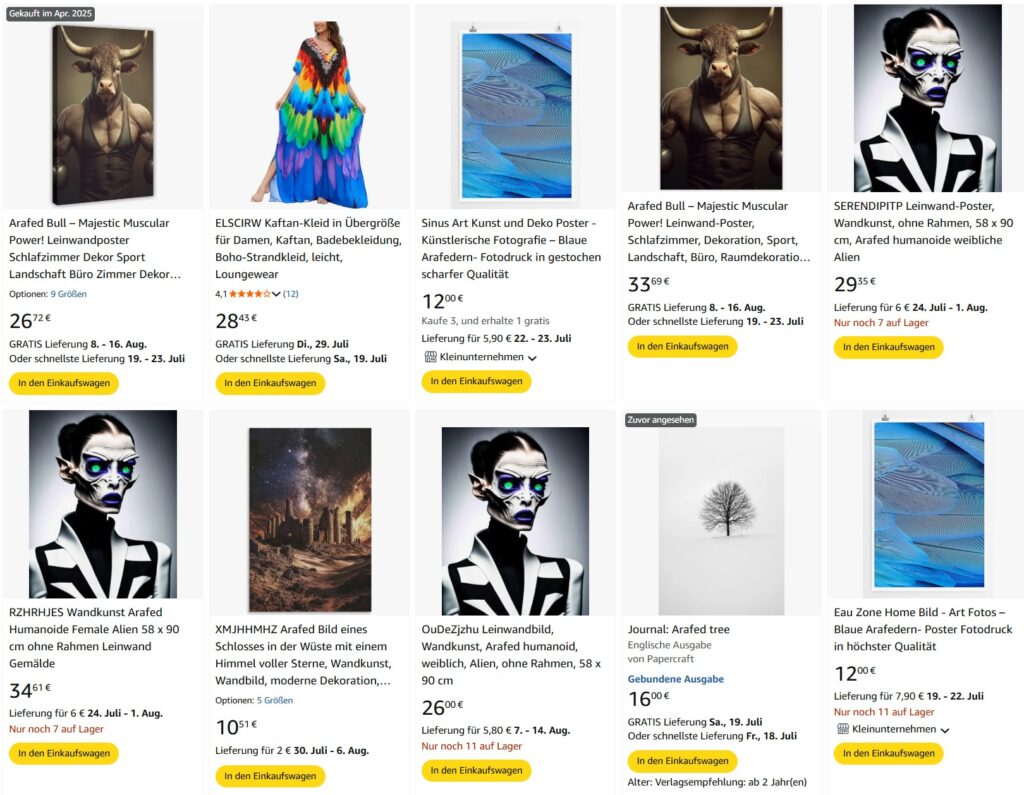
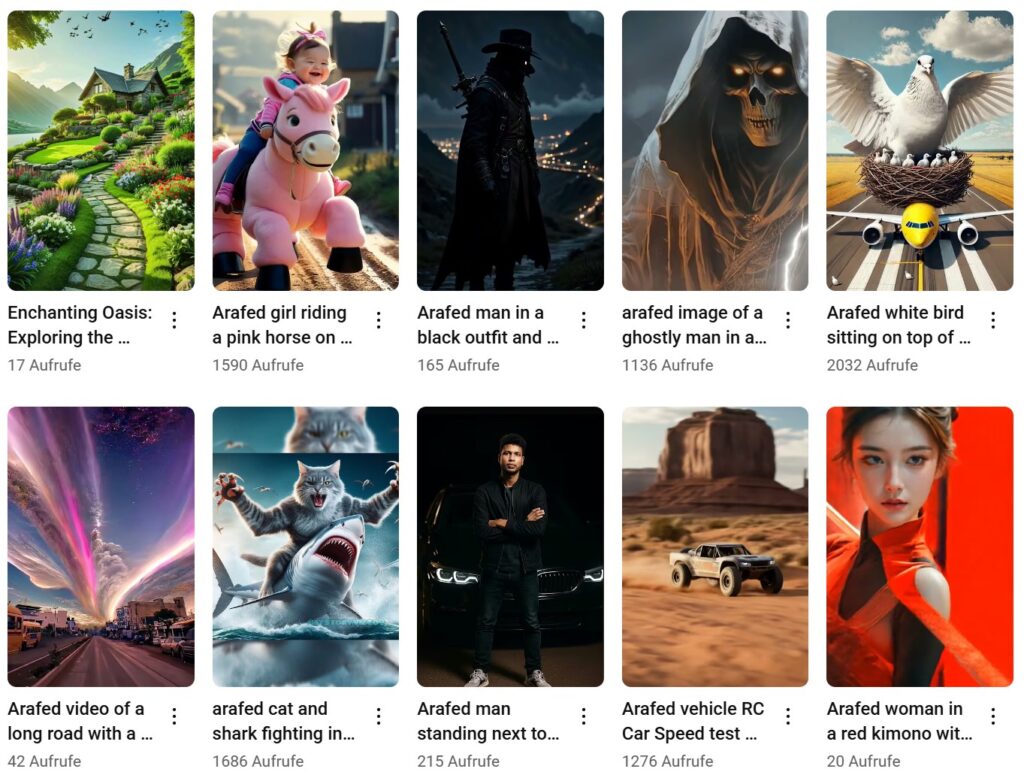
Diese Methode der Textumwandlung, wie sie in späteren Kapiteln beschrieben und gezeigt wird, ist nicht ohne ihre Tücken. Ein Phänomen, das eng mit dieser Sprachverarbeitung zusammenhängt, ist das Unwort „arafed“, eine Sequenz, die häufig in Aufforderungen oder Beschreibungen von scheinbar KI-generierten Bildern zu sehen ist. Es hat keine Definition in irgendeiner Sprache, ist in keinem Wörterbuch zu finden und taucht dennoch ständig überall auf, von Stock-Image-Seiten über soziale Medien bis hin zu Online-Shops. Die Suche nach diesem Begriff führt zu endlosen Mengen an generierten Inhalten und verwirrten Nutzern, die vergeblich versuchen, seine Bedeutung zu finden. Der Begriff hat seinen Ursprung in einem bestimmten Modell (BLIP), mit dem Textbeschreibungen von Bildern erstellt werden können. Es wurde daher von Menschen verwendet, um automatisch KI-Bilder zu kennzeichnen, die auf Stock-Image-Sites zum Verkauf angeboten werden, oder um mithilfe von Skripten automatisch Inhalte für soziale Medien zu generieren. Durch diese automatisierte Verwendung hat sich dieses Unwort, das auf ein Versehen in der Architektur des Modells zurückzuführen ist und inzwischen korrigiert wurde, verbreitet und Kanäle und Nutzer indirekt als automatisiert, nicht-menschlich oder als Bot gekennzeichnet. Da Internetinhalte unweigerlich zu Trainingsdaten für nachfolgende Modelle werden, wird „arafed“ vielleicht in Zukunft in den Wortschatz von Maschinen und vielleicht sogar von Menschen aufgenommen. Da das Gewicht der Gegenwart in den Datensätzen immer mehr zunimmt als das der Vergangenheit, muss man sich fragen, wann das zweite von der KI generierte Wort auftauchen wird. Im Folgenden werden einige Vorkommen des Wortes archiviert, von tatsächlich erhältlichen Produkten bis hin zu veröffentlichten Forschungsarbeiten – ein Zeichen für das, was noch kommen wird:
Die maschinengesteuerten Rückkopplungsschleifen sind bereits der Treibstoff für Content-Mühlen und Slop-Generatoren. Eine Verschwörung über ein zukünftiges Internet, das von Bot-gesteuerten Inhalten beherrscht wird, wurde als „The Dead Internet Theory“ bezeichnet, aber abgesehen von der Schwarzmalerei könnte „arafed“ zeigen, wie brüchig geschlossene Kreisläufe sind, da sich selbst winzige Veränderungen akkumulieren, auch wenn eine exponentielle Entwicklung nicht garantiert ist, da die Homöostase dieses Systems kurz bevorstehen könnte. Noch interessanter ist, dass einige Nutzer den Begriff „arafed“ übernommen haben, weil sie fälschlicherweise glauben, er müsse etwas bedeuten, da er so häufig vorkommt. Die populärste Definition, die durch ein ähnliches Wort im Urban Dictionary angeheizt wurde, war „gemächlich“ und bezog sich auf stereotype Darstellungen von Weiblichkeit, obwohl dies in der Praxis wenig bis gar keine Auswirkungen hat, da es vor 2022 noch nicht existierte und daher nicht Teil der meisten Trainingsdatensätze ist.
Generative artificial intelligence has split history into a before and an after. Since the advent of text generators like ChatGPT and image generators like Stable Diffusion, our shared digital artifacts have been under constant suspicion of being AI-generated. This wave of artificial intelligence systems is driven by what has been dubbed “natural language,” the subset of word combinations deemed part of human speech and text. But this implied language understanding is deceiving: hidden just beneath the first layer of interfaces is a machinery of moving parts and algorithms that transform natural language into chunks of symbols. These symbols, called tokens, are what communicate with trained deep neural networks and function as a quasi-protocol layer. The token vocabulary itself is generated through methods inspired by compression algorithms, resulting in some tokens that directly represent words and others that are merely series of special characters or codes, but also brand names and hashtags, since this machine language’s origins are texts meticulously crawled from the internet. Each token is represented by an integer ID starting with 0 and ending with a fixed number that represents the vocabulary length and is usually between 50000 and 150000.
This method of text conversion, as outlined and shown in later chapters, is not without its quirks. One phenomenon deeply linked to this language processing is the non-word “arafed” a sequence frequently observed in prompts or descriptions of seemingly AI-generated imagery. It has no definition in any language, is part of no dictionary, yet it constantly appears everywhere from stock-image sites and social media to online shops. Searching for it yields endless amounts of generated content and confused users trying to find its meaning to no avail. It originated in a particular model (BLIP) used to obtain textual descriptions of images. It has therefore been used by people to automatically label AI images for sale on stock-image sites or to auto-generate social-media content using scripts. Through this automated use, this non-word, which resulted from an oversight in the model’s architecture and has since been fixed, has spread and indirectly marked channels and users as automated, non-human, or bot. As internet content inevitably becomes training data for subsequent models, perhaps “arafed” will enter future machine, and maybe even human, vocabularies. Since the ever-increasing weight of the present in datasets outweighs what has come before, one must wonder when the second AI-generated word will emerge. The following archives some occurrences of the word, from actual products available for purchase to published research papers, a sign of what is to come:
The machine-driven feedback loops are already fueling content mills and slop generators. A conspiracy of a future internet dominated by bot-driven content has been called The Dead Internet Theory, but beyond the doomerism, “arafed” might show how brittle closed-circuit loops are, as even tiny shifts accumulate, although exponential development is not guaranteed, since the homeostasis of this system might lie just ahead. More interestingly, some users have adopted “arafed”, mistakenly believing it must mean something since it occurs so frequently. The most popular definition, fueled by a similar word on Urban Dictionary, has been as leisurely, relating it to stereotypical depictions of femininity, even though, in practice, since it did not exist before 2022 and is thus not part of most training datasets, it has little to no effect.