Disruptive News 21/1
13.04.2021, Christian Heck
subscribe to Newsletter »here«________________________
Todays Topics:
Creative AI | Computer Vision
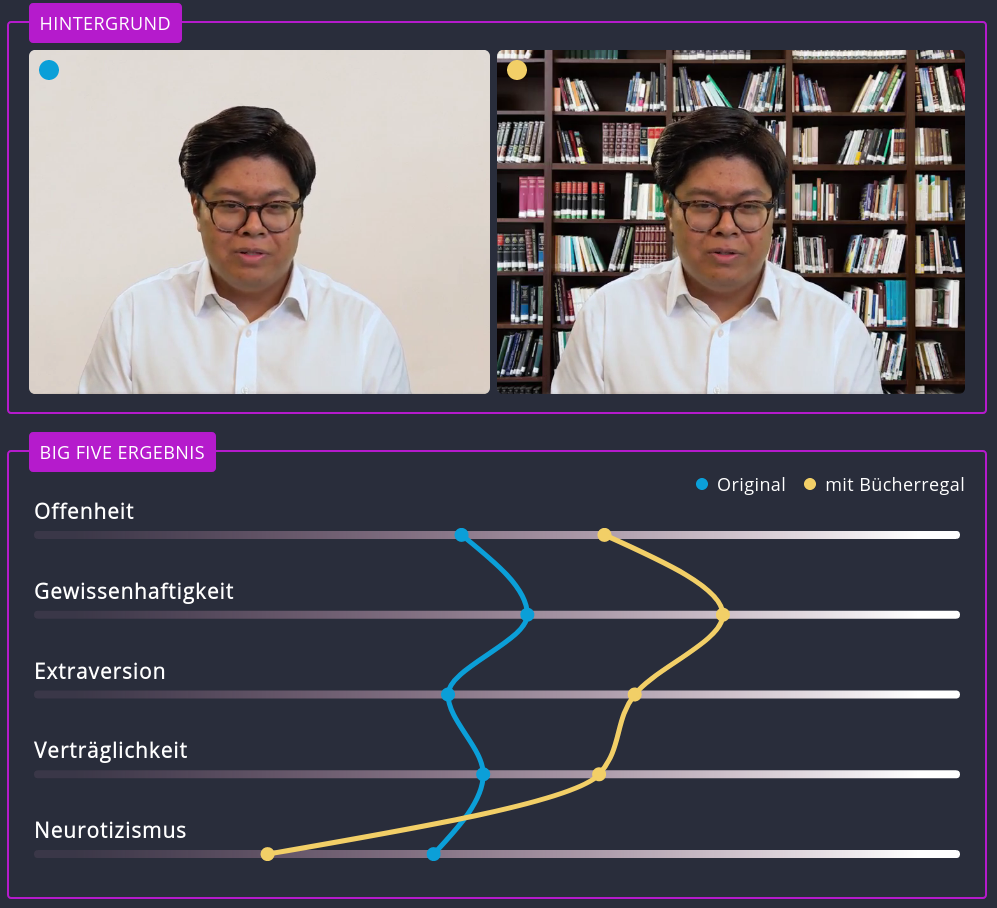
Während ich Ende Februar in den Videochatraum der diesjährigen Feststellungskommission II einstieg, unserer Kommission, die die eingegangenen Mappen für Diplom II begutachtet und BewerberInnen einlädt, schaltete sich auch gleich Kollege Johannes Wohnseifer mit ein. Ich laß kurz zuvor einen Artikel des Bayerischen Rundfunks über den sich – nach den USA – nun auch in Deutschland zu etablieren scheinenden Einsatz von KI-basierenden Systemen zur Vorauswahl von BewerberInnen. Wieder einmal entwickelte ein junges Start-Up-Unternehmen, mit finanzieller Unterstützung von u. a. Lufthansa, der BMW-Group und dem ADAC, ein applikatives Verfahren, um maschinell Persönlichkeitsprofile zu erstellen und auf Basis dessen zu entscheiden, wer den Job bekommt und wer nicht. Hierfür werden Mimik, Gestik und Sprache der BewerberInnen analysiert, um auf Basis deren Persönlichkeitsmerkmale abzuleiten. Unter anderem testete das Team des Bayerischen Rundfunks Reaktionen des Systems auf verschiedene Hintergründe und fand heraus, dass z.B. die Verwendung eines Bücherregals die BewerberInnen sehr viel gewissenhafter, offener und allgemein verträglicher errechnet.

Kollege Wohnseifer, Professor für Malerei und Skulptur, hatte zwischen all seinen Büchern im Hintergrund ein schwarzes Quadrat hängen. Auch wenn es sich nach eigener Aussage nicht um einen Malewitsch handelt, sondern um ein späteres Gemälde der Künstlerin Michaela Eichwald, so stellte sich mir an dieser Stelle doch die Frage, ob das schwarze Quadrat ein weiteres Mal dazu in der Lage sei, uns hin zu einem ground zero der Kunst zu führen, diesmal in der digitalen, der generativen, der Computer Vision, diesmal in der Kunsthochschule für Medien Köln?

In dem soeben veröffentlichten Datensatz ArtEmis: Affective Language for Visual Art jedenfalls kommt Malewitschs „Schwarzes Quadrat“ nicht vor. Dieser konzentriert sich auf affektives Erleben, das durch visuelle Kunstwerke ausgelöst werden soll. Das rechts platzierte GIF zeigt ein paar exemplarische Outputs eines Deep-Learning-Systems, das geschrieben wurde, um aus diesem Datensatz heraus subjektive Interpretationen von Kunst zu erzeugen. Ein Roboter-Rezensent sozusagen, der 81.500 Gemälde aus der Online-Enzyklopädie für visuelle Künste WikiArt mit Schlagwörtern kombiniert. Diese beschreiben den emotionalen Charakter eines jeden Werks und werden mit kurzen Erklärungen, wie das Werk diese Emotionen hervorgerufen haben soll, dargestellt.
Viele ForscherInnen und KünstlerInnen, die sich in zeitgenössische Debatten zu Creative AI heute einbringen, nutzen solch große Datenbanken. Auch im Falle des »Portrait of Edmond Belamy«, wohl das erste von einer KI generierte Kunstwerk, das für internationale Aufmerksamkeit sorgte, griff das französische Künstlerkollektiv „Obvious“ auf den Datensatz WikiArt zu, um ihren Künstlichen Neuronalen Netzen Trainingsmaterial zu liefern.

Der wohl größte Zulieferer an Datensätzen zum Trainieren von Deep-Learning-Systemen ist Amazon Mechanical Turk (MTurk). Ein Mikrodienstleistungsservice von Amazon, bei dem Freischaffende für Centbeträge Kleinstaufträge ausführen. Er wird häufig als ‘die künstliche künstliche Intelligenz’ bezeichnet. Ca. 500.000 Menschen aus 190 Nationen führen tagtäglich unzählige HITs (Human Intelligence Tasks) aus, die maßgeblich zur Qualität des jeweiligen KI-Modells und somit zum evaluierten Output, dem was neu gerahmt dann als Kunstwerk in Erscheinung treten wird, beiträgt.
“Wenn in Schwitters i-Zeichnungen durch die Auswahl und Größe des Bildausschnittes sowie das Datieren, Betiteln und Signieren diese Bilder zu Kunst erklärt werden, wie verhält sich dieses Prinzip (Muster) im Vergleich zur Kunstproduktion z.B. mit Hilfe des GAN-Algorithmus?“, fragte Verena Lercher im Sommer letzten Jahres in ihrer Diplomarbeit »Can AI do Dada?«.
Was mit diesen meist im Verborgenen agierenden menschlichen ArbeiterInnen geschieht, jenen, die das Datenmaterial der ‘Künstlichen Kunst’ fertigen, dieser Frage widmete sich die Berliner Gazette in ihrem Jahresprojekt »Silent Works«. In Texten, Videos und Projekten machte sie diese Ende 2020 sichtbar.
Das Künstlerkollektiv Obvious und Mattis Kuhn sprachen vor einigen Tagen in einem kurzen aber klaren WDR-Beitrag »Rechnen statt malen – Künstliche Intelligenz als Künstler« über Fragen hinsichtlich solcher Schaffensprozesse und ob KI die Kunst zum ground zero führe?
Kurz nachdem vor drei Jahren das »Portrait of Edmond Belamy« für 432.500 Dollar bei Christies versteigert wurde, kommentierte der internationale Leiter für Drucke und Multiples bei Christie’s, Richard Lloyd die Auktion in seinem Hause wie folgt: “Auch wenn das Belamy-Porträt nicht von einem Menschen in gepuderter Perücke angefertigt worden ist, so entspricht es doch exakt der Art von Kunst, wie sie seit 250 Jahren zum Verkauf steht.“
Hier werden vage Vulgarisierungen der Rezeptionsästhetik der 1980er und 90er Jahre wach, wonach Kunst erst „im Auge des Betrachters“ oder im Ohr und Urteil des Lesers oder Hörers entstehe. “Everybody has their own definition of a work of art. If people find it charged and inspiring then it is.” zitiert bspw. Arthur I Miller den Leiter Richard Lloyd von Christie’s; und weiter: “To me, art is judged by the reactions people have”. Die Unschuld in diesen Äußerungen, deren expliziter Subjektivismus wahrlich schwer zu überbieten ist, resigniert de facto vor dem Problem, bei diesem Genre überhaupt einen adäquaten Kunstbegriff angeben zu können.
Computer Vision | Curating

Einen adäquaten Kunstgriff hingegen könnte eine bewusste Setzung einer Künstlichen Intelligenz als Kunstsammler oder Kurator darstellen:
Liz Haas und Hans Bernhard, das Künstlerkollektiv UBERMORGEN und KHM-Professoren für Netze haben gemeinsam mit der Kuratorin Joasia Krysa und dem digital humanist Leonardo Impett eine solche KI geschrieben: „Die Software B 3 (NSCAM) verwendet unter anderem Datensätze der Liverpool Biennial und des Whitney Museum. Es verarbeitet sie sprachlich und semiotisch und berechnet eine zukünftige Wahrscheinlichkeit für das Erscheinen von Wörtern, um endlose Kombinationen möglicher Instanzen von Biennalen im Fluss zu generieren. Diese imaginären Ereignisse manifestieren sich als Texte – scheinbar konventionelle Künstlerbiografien, kuratorische Aussagen, Pressemitteilungen und Rezensionen von Kunstmagazinen -, die sich kontinuierlich neu schreiben.“ Gerade eben wurde diese Arbeit im Whitney Museum of American Art und in der Liverpool Biennale 2021 ausgestellt. Im Gegensatz zu zahlreichen zeitgenössischen Ansätzen des KI-Kuratoriums, wie beispielsweise »Recognition« vom Tate Britain Museum in London in Zusammenarbeit mit Microsoft und Reuters, oder »Qurator –A Flexible AI Platform for the Adaptive Analysis and Creative Generation of Digital Content«, einem staatlich gefördertem (BMBF) Forschungsprojekt mit Partnern wie dem Fraunhofer Institut, Ubermetrics, der Staatsbibliothek zu Berlin oder Wikimedia Deutschland, einer künstlerisch-aktivistischen Praktik in Anwendung von Brechts ‘Verfremdungseffekt’ gleich, einer frühen avantgardistischen und auch altbewährten subversiven Differenzerfahrungstaktik, um den Betrachtern Einsicht in die jeweiligen Verhältnisse zu gewähren und ihnen auf diesem Wege ihre Veränderbarkeit begreifen lassen.
Critics² Artificial Art
Über diese Thematik schrieben wir unter anderem in dem kürzlich erschienenen Kommentar zum Artikel »(Un)creative Artificial Intelligence. Zur Kritik ‘künstlicher Kunst’« von Dieter Mersch. Mersch kritisiert darin vor allem neuere Kunstprojekte, die von KI-Algorithmen produziert werden, die also beispielsweise auf ‘deep learning’ und generativen Verfahren beruhen. Diese ‘artificial artefacts’ basieren seiner Ansicht nach sowohl auf einem naiven Konzept von Kunst, als auch auf einem reduzierten Verständnis menschlicher und maschineller Kreativität. Seinen Analysen kann man in vielen Punkten durchaus zustimmen. Manches, das er kritisiert, wird auch innerhalb der KI-Forschungsgemeinde und der Kunst seit langem kontrovers diskutiert, und das nicht erst seit ‘deep learning’ und ‘Big Data’ die Massenmedien erreicht haben. Einen Kommentar unsererseits hat der Aufsatz provoziert, weil hier ein zu enges Verständnis von Algorithmik und Kunst zum Tragen kommt, das am Ende das Kind mit dem Bade ausschüttet.
Creative AI | Surveillance

Was häufig hinter solch Forschungsansätzen zur Erstellung von subjektiven Interpretationen und Persönlichkeitsprofilen durch Computer Vision steckt, zählt zu dem Forschungsteilbereich Emotional AI. Unter anderem untersucht dieser die emotionale Wirkung von (digital[isiert]en) Bildern auf den Menschen. Auf Chefs, auf PolizistInnen auf SozialwissenschaftlerInnen, auf KunstrezensentInnen und weitere Akteure.

In den letzten Jahren wurden zahlreiche KI-Systeme entwickelt um Beziehungen zwischen Bildern und Emotionen zu untersuchen, insbesondere Bilder von menschlichen Gesichtern. Ein Beispiel ist ein GAN (Generative Adversarial Network), das entwickelt wurde um synthetische Gesichter zu erzeugen, die verschiedene Emotionen auszudrücken.

Dank einiger Monopolstellungen in den Creative Industries ist es uns Künstlerinnen und Künstlern möglich jederzeit den kürzesten Weg zu nehmen, aus den Forschungslaboren heraus zu marktfähigen Creative-Apps mit “neuronalen Filtern” z.B. in Adobe Photoshop

oder dem MetaHuman Creator von Epic Games, “ein neues Tool, mit dem jeder in wenigen Minuten einen maßgeschneiderten fotorealistischen digitalen Menschen erstellen kann, komplett ausgestattet mit Haaren und Kleidung.”.

Im Wintersemester 19/20 war Matthias Burba zu Gast im KHM-Biolab. Burba, ehemaliger Leiter der Kriminaltechnik der Hamburger Polizei berichtete dort u.a. zum aktuellen Stand der “DNA-Phänotypisierung” in der polizeidienstlichen Anwendung. Eine Anwendung von Verfahren, mit denen auf Basis von DNA-Material Rückschlüsse über das äußere Erscheinungsbild eines Individuums gezogen werden können.

Diese sogenannte „erweiterte DNA-Analyse” für den Polizeialltag ist in Deutschland noch verboten. Eine entsprechende Gesetzesänderung zu deren zukünftiger Anwendung im Strafverfahren ist jedoch schon seit längerem in Planung. Mittels „genetischer Phantombilder“ sollen Eigenschaften wie das äußere Erscheinungsbild, Alter sowie die bio-geografische Herkunft von Verdächtigten etc. nicht nur vorhergesagt, sondern auch dargestellt werden.
Nach eigenen Angaben verfügt China derzeit noch über die weltweit größte DNA-Datenbank mit mehr als 80 Millionen Profilen. Die chinesische Regierung ist die erste Regierung, die Technologien aus der KI-Forschung explizit für Racial Profiling nutzt und dafür seit ca. zwei Jahren auch eine starke mediale Aufmerksamkeit erhält. Teilweise so stark, dass Verfahren westlicher Staaten und Behörden oft in den Hintergrund rückten, so wie etwa sexistische und rassistische Bias in AI-Computer Vision Systemen von Microsoft oder Amazon.

Der seit Ende 2016 bestehende Softwaredienst Recognition des letztgenannten Onlinehandelsriesen kann unter anderem Objekte, Gesichter, Basisemotionen und Laufwege in Fotos und Videos erkennen und analysieren. Die amerikanische Bürgerrechtsvereinigung ACLU kritisierte öffentlich den Cloud Anbieter Amazon Web Services (AWS) für den Betrieb dieses Internetdienstes. Auch der Kern dieses Tools liegt in der Technologie des deep learning. Unser Bundesinnenministerium bestätigte auf Anfrage im Jahr 2019 die Speicherung der Daten von sogenannten Bodycams, die am Körper von im Einsatz befindenden BundespolizistInnen getragen werden, in einem Cloud-Angebot von Amazon Web Services.

Timnit Gebru, die ehemalige Leiterin von Googles Ethical AI Intelligence Team, wies 2018 gemeinsam mit der Informatikerin Joy Buolamwini vom MIT Media Lab in ihrem Forschungspaper »Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification« nach, dass kommerzielle Systeme zur automatischen Gesichtserkennung für Menschen mit nicht-weißer Hautfarbe sowie weibliche Personen signifikant schlechter funktionieren als für weiße, männliche Personen. Die Forschungsergebnisse sind bis heute noch zugänglich und übersichtlich auf der Projektwebseite http://gendershades.org/ dargestellt. Die Einteilung von Menschen nach physischen Merkmalen in unterschiedliche Gruppen („Rassen“) ist sozusagen ein „Kern“ von Rassismus. Dabei werden aus einer Vielzahl visuell sichtbarer körperlicher Eigenschaften einzelne Merkmale herausgegriffen und Grenzen zwischen den variierenden körperlichen Merkmalen von Menschen gezogen. Auf dieser Grundlage werden Menschen auch in ihrem Wesen unterschieden und ihnen pauschal bestimmte soziale oder kulturelle Eigenschaften oder Verhaltensmuster zugeschrieben, so Susan Arndt in ihrem umfangreichen Nachschlagewert »Wie Rassismus aus Wörtern spricht«, 2019 im Unrast Verlag.
Chinas Gesichtserkennungssysteme sind in zahlreichen Städten darauf ausgerichtet, Mitglieder der Minderheit der Uiguren automatisch zu erkennen und zu tracken. Seit 2017 ist bekannt, dass die Chinesische Regierung die biometrischen Daten aller Uiguren zwischen 12 und 65 Jahren erfassen ließ. Hierzu gehören Blutgruppe. Fotos des Gesichtes, ein Iris-Scan, Fingerabdrücke und die DNA.
Surveillance | Subversion

U.a. berichteten hierzu das Redaktionskollektiv çapulcu, eine Gruppe von technologie-kritischen AktivistInnen und HacktivistInnen in ihrem fünften Band aus der Reihe „Hefte zur Förderung des Widerstands gegen den Technologischen Angriff“. Sie veröffentlichten ihn inmitten der Coronakrise mit dem Titel DIVERGE! – Abweichendes vom rückschrittlichen „Fortschritt“.
Lars von çapulcu wurde in den letzten Jahren mehrere Male in die KHM eingeladen, um an Seminaren mit Vorträgen, Diskussionsrunden (1, 2) und Podcasts (3) bei Netze und Experimentelle Informatik teilzunehmen

Auch aus dem medienaktivistischen Umfeld war Jean Peters, Aktionskünstler und Gründungsmitglied des Peng! Kollektivs, im vorigen Jahr eingeladen am KHM-Podcast Octopus teilzunehmen, in dem er über seine ganz eigene Art des Batteling the barbarism of our time mit Sam Hopkins diskutierte. Jean Peters schrieb zu dieser Zeit schon an seinem Buch Wenn die Hoffnung stirbt, geht’s trotzdem weiter. Ein gelungenes Buch mit lesenswerten Erzählungen aus dem »subversiven Widerstand« u.a. gegen die Waffen- und Überwachungsindustrie á la Google und Heckler & Koch, gegen NSA, dem BND, die AFD und (weitere) gesellschaftliche Missstände. “In den Geschichten geht es darum, Machtdiskurse zu unterwandern und Widerstand gegen diesen Schlachthof zu leisten, den wir als kapitalistische Sachherrschaft über Mensch und Natur kennen. Subversion und Widerstand als gezielte mediale Interventionen, die sich mit den aktuellen Verhältnissen nicht einverstanden geben wollen, sondern unser im Jetzt verfangenes Denken freisprengen, konkrete Utopien greifbarer und begehrbarer machen sollen.”
Binary | Glitch

Auch der Glitch Feminismus von Legacy Russel stellt eine strategische Subversion in a digital age dar und “verlangt ein Besetzen des Digitalen, als einer Methode des Weltenbaus.”

Glitch Feminismus, so Russel in der im April im Merve Verlag erscheinenden deutschen Übersetzung ihres Buchs Glitch Feminism – A Manifesto, erkundet nicht einzig die Beziehung von Gender, Technologie und Identität, sondern sie betrachtet eine technische Fehlfunktion, den Glitch, als eine Fortbewegungsform der Verweigerung, als einen Ausgangspunkt, um singuläre Identitäten in kollektive Vernetzungsformen umzugestalten: “Der Glitch zielt darauf ab, etwas wieder abstrakt zu machen, was einem unbehaglichen und unzureichend definierten Material aufgezwungen wurde: dem Körper. In Glitch Feminismus betrachten wir die Idee von Glitch-als-Fehler mit ihren Ursprüngen im Reich des Maschinellen und des Digitalen, und überlegen, wie sie neu angewendet werden kann, um einen Einfluss auszuüben auf die Art, wie wir die Welt AFK sehen, und Arten zu formen, auf die wir in ihr teilnehmen können und mehr Handlungsspielraum für und durch uns selbst entwickeln. Glitch Feminismus lässt das Internet als kreatives Material auf die Welt los, und schaut zuerst durch die Linse von Künstler:innen, die in ihrer Arbeit und ihrer Forschung diesem bedrängten Material Körper Lösungen anbieten. Der Prozess der Materialwerdung bringt Spannungen an die Oberfläche und führt uns zu der Frage: Wer definiert das Material des Körpers? Wer gibt ihm Wert – und warum?“.
Sich von Binaries und Binärcodes zu befreien, dem widmete sich auch die Live-Performance „Queer Dada“ am 30. März 2021 mit ihrer Ode an die Fluidität im Dada-Stil gewidmet. Ein Trans-Raum voll von queeren, nicht-binären und trans-menschlichen Kreaturen, jenseits von kulturellen Grenzen, Geschlechter-Binaritäten und Gewalten des Anthropozäns.
Biometric | Megapixels

Eine andere Strategie wählte der Medienkünstler und Computer Vision Forscher Adam Harvey zusammen mit dem Coder und Künstler Jules LaPlace. Die Beiden entwickelten gemeinsam die Search Engine Exposing.ai.
Dieses Online-Tool basiert größtenteils auf Megapixels , einem Projekt welches Ethik, Herkunft und die individuellen Auswirkungen von Gesichtserkennungs-Bildtrainingsdatensätzen auf die Privatsphäre untersucht, sowie auch deren Rolle bei der Expansion biometrischer Überwachungstechnologien. Megapixels untersuchte den größten öffentlich verfügbaren Gesichtserkennungsdatensatz MegaFace, der aus 3,5 Millionen Bildern aus Flickr.com besteht und unter Creative Commons lizenziert wurde.
Mit Exposing.ai können NutzerInnen Bilddatensätze zur Gesichtserkennung durchsuchen um zu erfahren ob eigene Fotos in der Vergangenheit benutzt wurden um Gesichtserkennungs-Tools weiterzuentwickeln.

Das Projekt wurde Ende Januar 2021 gestartet.
Im Februar 2021 initiierte der Konzeptkünstler Paolo Cirio zusammen mit der französischen Non-Profit-Organisation La Quadrature du Net (LQDN) und dank der Recherchen der European Digital Rights advocacy group (EDRi) die Kampagne Ban Facial Recognition Europe. Sie zielt darauf ab, nicht nur die Gesichtserkennung zu verbieten, sondern alle biometrischen Technologien die eine Massenüberwachung und eine Diskriminierung gesellschaftlicher Subjekte ermöglichen. Die Implementierung der Gesichtserkennung in Europa hat zu schwerwiegenden Verstößen gegen Grundrechte, mangelnder Rechenschaftspflicht sowie auch zu einer teils uferlosen Verschwendung öffentlicher Gelder durch europäische Institutionen geführt.
Fight | Fascism
Komplexe Themen, die schwer zu erklären sind und viele Menschen betreffen, bieten einen außerordentlich fruchtbaren Boden für allerlei Spekulatives, Verschwörungsmythen und rassistische Auswüchse in der Gesellschaft. Die Washington Post veröffentlichte Anfang März 2021 Ergebnisse einer internen Facebook-Studie, die zeigt, dass beispielsweise eine sehr geringe Zahl von Impfgegner:innen gezielt eine große Anzahl anderer Menschen verunsichern kann. So müssen die einen in soziotechnischen Netzwerken á la Facebook sich den Codes und Gesetzen dieser Plattformen weniger anpassen, im Gegenteil, ihre Provokationen, Verschwörungstheorien und rassistischen Sprachgebräuche werden sogar algorithmisch gefördert. Dies wurde u. a. gut strukturiert und übersichtlich in dem 2020 erschienen Buch Digitaler Faschismus dargestellt. Andere wiederum werden von den Rating- und Ranking-Algorithmen quasi unsichtbar gemacht. So tauchten in Facebook beispielsweise in den Jahren 2014 und 2015 die Vorkommnisse in der US-amerikanischen Stadt Ferguson praktisch nicht auf, in der am 9.8.2014 der 18-jährige afroamerikanische Schüler Michael Brown bei einer Polizeikontrolle erschossen wurde und sich kurz darauf die Stimmung in der Stadt dermaßen aufheizte, dass es zu Straßenschlachten und Plünderungen kam. Die Vorkommnisse traten in Facebook nicht etwa nicht in Erscheinung, weil sie nicht spektakulär genug gewesen wären, im Gegenteil. Die Aufstandsbekämpfung nach dem Mord an Michael Brown war martialisch. Die örtliche Polizei setzte Panzerfahrzeuge, Blendgranaten, Rauchbomben, Tränengas sowie Gummigeschosse gegen die aufgebrachte Menge ein.
Aber der FB-Edgerank-Algorithmus filterte das Thema aus, da er laut Facebook die Neuigkeiten nach personalisierter Relevanz aufbereitet. Black Lives Matter wurde somit in diesem soziotechnischen Netzwerk quasi unsichtbar.
„Algorithmen sind weder „neutral“ noch „objektiv“, auch wenn wir das gerne glauben wollen. Sie reproduzieren die Annahmen und Überzeugungen jener, die sich dafür entscheiden, sie einzusetzen und zu programmieren. Aus diesem Grund sind für die Auswahl guter wie schlechter Algorithmen Menschen verantwortlich (oder sollten es sein) und nicht „Algorithmen“ oder ADM-Systeme. Maschinen mögen uns Angst machen, doch der Geist, der ihnen innewohnt, ist stets ein menschlicher.“, so heißt es in dem im Januar 2021 in deutscher Sprache erschienenem Automating Society Report 2020 der gemeinnützigem Forschungsvereinigung Algorithm Watch.

Dual | Use
Wie wir diesen neuen und aber auch ganz alten und etablierten Technologien, denen wir immer mehr Handlungsmacht in unserem Lebensalltag, Wirk- und Entscheidungsmacht über Leben und Tod übertragen, wie wir über diese ebenbürtig debattieren können,
gerade hinsichtlich jener Technologien, die ganz bewußt zur Überwachung gesellschaftlicher Subjekte und der Kriegsführung erforscht und entwickelt werden,
aber auch jene die hinter dem Begriff DUAL USE stecken. Der DUAL USE ist längst ein nicht wegzudenkender Teil unserer Wirklichkeit geworden. Auch, wenn wir diesen nicht immer sehen können, zumindest nicht im Sinne von intellegere, von ‘einsehen’ von ‘erkennen’.
Die Bundesregierung drängt in der KI-Forschung immer stärker auf eine schnelle Umsetzung neuester Forschungsergebnisse in die Praxis und kommerzieller Nutzung von der Grundlagenforschung ganz schnell in einen applikativen Alltag hinein. Schon seit einigen Jahren lässt sie hierfür mit dem Label »AI made in Germany« KI-Kompetenzzentren bauen, Konvergenzen wirtschaftlicher und staatlicher Lenkungsinteressen, öffentliche, oft auch militärisch-industrielle Forschungsblackboxen wie auch das Cyber Valley in Tübingen eines ist. Über diese derzeit größte KI-Forschungskooperation Europas nach dem Vorbild Silicon Valley diskutierten wir vor ca. 1,5 Jahren in der Experimentellen Informatik gemeinsam mit Christoph Marischka von der Informationsstelle Militarisierung (IMI) im Zuge seines Vortrags Wo beginnt der Krieg?. Christoph Marischka verfasste Ende letzten Jahres eine lesenswerte Studie zu Künstlichen Intelligenzen im Militärbereich »Künstliche Intelligenz in der Europäischen Verteidigung: Eine autonome Aufrüstung?«.

Er referierte vor einigen Tagen auch wieder in Köln -nur diesmal virtuell- und zum Thema “DUAL USE: der (gut organisierte) Transfer ziviler Forschung in militärische Anwendungen”.
Senta Pineau aus dem Arbeitskreis Köln der Initiative “Hochschulen für den Frieden – Ja zur Zivilklausel”, initiierte am 9. März die Online-Veranstaltung “Sag Nein! Der aufhaltsame Aufstieg der Militarisierung mit Künstlicher Intelligenz”.
Unter anderem wurde dort über das Kampfflugzeugsystem „Future Combat Air System“ (FCAS) informiert und diskutiert. Ein deutsch-französisch-spanisches Großprojekt das vor allem auf die militärische Nutzung von Künstlicher Intelligenz setzt. Die Bundesrepublik ist hierbei an der Entwicklung eines europäischen Kampfflugsystems beteiligt, das aus neuartigen Kampfflugzeugen besteht, die Atomwaffen tragen und die mit bewaffneten „Eurodrohnen“ und weiteren im Schwarm fliegenden bewaffneten autonomen Drohnen, vernetzt werden sollen.
AI | Warfare
Nicht nur völkerrechtlich ist diese Entwicklung hin zu autonomen Kampfdrohnen höchst fragwürdig, sprich bewaffnete Drohnen die algorithmisch gelenkt und teils auch aus ihnen heraus feuern.
Als die Präsidentin der Europäischen Kommission Ursula von der Leyen im Jahre 2013 den Posten zur Verteidigungsministerin annahm, formulierte sie ihre Zielsetzung in Sachen Kampfdrohnen bei einem Truppenbesuch im nordafghanischen Mazar-i-Scharif zu ihren SoldatInnen folgendermaßen: „Das wichtigste ist der Mensch und nicht die Frage der Materialkosten“. Zum eigenen Schutze und zum Schutz der Bevölkerung müssen unsere SoldatInnen mit “modernstem Material” ausgestattet sein.
Damals setzte die Bundeswehr schon seit drei Jahren nicht-bewaffnungsfähige „Heron 1“-Drohnen in Afghanistan ein. 2018 leaste die Bundeswehr bewaffnungsfähige „Heron TP“-Drohnen. Die Regierungskoalition wollte deren Bewaffnung vor den Weihnachtsferien vom Bundestag beschließen lassen. Dank selbstorganisierten Friedenskräften wie der Informationsstelle Militarisierung, die Drohnen-Kampagne, Stopp Air Base Ramstein u.v.w. konnte die Bewaffnung im Dezember vorläufig gestoppt werden und trat der Atomwaffenverbotsvertrag im Januar in Kraft.

–
Ein generelles Verbot KI-gestützter autonomer Waffen ist hingegen noch lange nicht in Sicht. Erst im Januar sprach sich ein von der US-Regierung eingesetztes Gremium von KI-ExpertInnen dagegen aus. Der Entwurf eines Berichts der National Security Commission on Artificial Intelligence, die vom ehemaligen Google-CEO Eric Schmidt geleitet wird, spricht sich gegen ein internationales globales Verbot von KI-gestützten autonomen Waffensystemen aus. Eine Idee, der über 30 andere Länder (Deutschland gehört nicht dazu) zugestimmt haben.
Friedensbündnisse und Nichtregierungsorganisationen wie the Campaign to Stop Killer Robots setzen sich seit fast einem Jahrzehnt für ein Verbot autonomer Waffen ein. Die Vereinten Nationen treffen sich seit 2014 zu diesem Thema.
Natural | Language –
Wie sprechen wir im internationalen Austausch über KI und ihre breitgefächerten Einsatzgebiete?
Am besten in Englisch.

Nicht nur, dass die meisten KI-Sprachmodelle speziell für die englische Sprache geschrieben wurden, nein Englisch ist auch die unter Computerlinguisten und den Digital Humanities am häufigsten benutzte Sprache. Generell gilt sie als die Sprache der internationalen wissenschaftlichen Kommunikation.
Des Weiteren ist die englische Sprache eine sehr analytische Sprache mit einer ziemlich strengen Wortreihenfolge. Deshalb werden die auf der Theorie der formalen Sprachen basierenden Algorithmen erfolgreicher auf isolierende Sprachen wie dem Englischen angewendet, als z. B. auf den Sprachtypus der flektierenden Sprachen, unter dem auch z. B. die deutsche Sprache steht. Diese zeichnen sich u. a. dadurch aus, dass Lautwechsel im Stamm auftreten und Affixe (auch Beisilben genannt, Lautelemente mit einer eigenen Bedeutung) mit dem Stamm verschmelzen können. Dies bietet, im Gegensatz zu den isolierenden Sprachen, einen deutlich größeren Spielraum in der Wortreihenfolge. Und stellt aber auch sehr große Hindernisse bei der maschinellen Übersetzung zwischen diesen beiden Sprachen dar.
| Poetry
Sicherlich sind die meisten von uns in den letzten Monaten beim Zeitunglesen mindestens einmal auf die beiden Namen Timnit Gebru und Amanda Gorman gestoßen.

Amanda Gorman trug kurz vor Bidens Amtseinführung ihr Gedicht mit dem Titel „The hill we climb“ vor. Am Dienstag, den 30. März 2021 erschien die deutsche Übersetzung. In den letzten Wochen wurde eine lautstarke Debatte über mögliche Übersetzungen dieses Gedichts in den internationalen Medien geführt, nachdem die für die niederländische Übersetzung zunächst vorgesehene Schriftstellerin Marieke Lucas Rijneveld von dem Übersetzungsauftrag zurückgetreten ist. Die darauffolgenden Debatten, die durch einen Artikel der niederländischen Autorin Janice Deul in der Volkskrant quasi getriggert wurden, kann man kurz mit dem Titel überschreiben: „Dürfen Weiße Schwarze übersetzen?“. Auch wenn darin nicht wirklich die Rede davon war, dass nur Schwarze Schwarze übersetzen sollen dürfen. Es ging ihr in erster Linie nur um dieses eine spezifische Gedicht von Amanda Gorman in dem Zusammenhang Black Lives Matter.
Es ist sehr interessant, sich den zahlreichen Fragen, die in dieser Debatte in Erscheinung traten zu widmen, bevor wir nochmals zu Timnit Gebru überleiten, der ehemaligen Leiterin von Googles Ethical AI Intelligence Team: „Müssen Übersetzer:innen immer aus der Gruppe der Originalverfasser:innen sein? Und wenn ja, welche Kategorien sind relevant? Können nur Schwarze die Texte von Schwarzen übersetzen? Nur Frauen die Texte von Frauen? Und wie ist es mit einem Text von einer Schwarzen Frau: ist ein Schwarzer Mann oder eine weiße Frau besser geeignet? Und vor allem: Wer entscheidet das?“. Siehe hierzu auch den folgenden Essay der Autorin Saba-Nur Cheema, der kürzlich in der Taz erschien.
Fragen nach der kulturellen Identität wurden neben breite Diskussionen über die literarische, bzw. die künstlerische Aneignung gestellt. In wie weit profitieren Künstlerinnen und Künstler, deren Arbeit sich mit den Erfahrungen marginalisierter Gruppen auseinandersetzt, dessen Erfahrungskreis und Community diese aber selbst nicht teilen? Wichtige Fragen, die allesamt nicht vereinfacht noch leichtfertig beantwortet werden dürfen. Der britische Soziologe Stuart Hall warnte einst vor einem essentialistischen Verständnis von Identität. In seiner Theorie ist kulturelle Identität nicht statisch, gegeben oder absolut, sondern ein ständiger und immer unabgeschlossener Prozess. Die gemeinsame Vergangenheit schafft einen imaginären Zusammenhalt, quasi eine Schicksalsgemeinschaft, die jedoch nicht bedeutet, dass die unterschiedlichen Lebensrealitäten und Interessen in der Gegenwart keine Rolle mehr spielen.
Und rein fachlich? Was ist mit Fragen nach fachlichen Kompetenzen jeweiliger eher schlecht als recht bezahlten ÜbersetzerInnen? Diese sind “ist im jeweiligen Einzelfall zu klären”, und zwar “welche ÜbersetzerInnen für den jeweiligen Text am besten geeignet sind” so der Übersetzer Frank Heibert, der im Onlinefeuilleton von Tell-Review eine eingehende Auseinandersetzung hierzu veröffentlicht hat. Er telefonierte vor einigen Tagen mit Dirk Knipphals von der taz. Heibert zählt darin auf: “Expertise im jeweiligen Genre ist wichtig. Die Neugier auf den gedanklichen Hintergrund des Textes ebenso. Biografische Hintergründe, die Frage des Geschlechts, das alles kann hineinspielen, und geteilte Erfahrungshintergründe können es eben auch. (…) Die sprachlichen und stilistischen Fertigkeiten”.
Das alles wo es doch so einfach wäre…:
Ein Klick auf https://translate.google.com/?hl=de
Und aus Amanda Gormans “The Hill We Climb” würde “Der Hügel, den wir erklimmen”.
Und aus den ersten Zeilen des Gedichts:
“When day comes, we ask ourselves, \ where can we find light in this never-ending shade? \ The loss we carry, \ a sea we must wade. \ We’ve braved the belly of the beast. \ We’ve learned that quiet isn’t always peace. \ And the norms and notions \ of what just is, isn’t always just-ice.”
würde:
“Wenn der Tag kommt, fragen wir uns: \ Wo finden wir Licht in diesem unendlichen Schatten? \ Der Verlust, den wir tragen, \ Ein Meer, das wir waten müssen. \ Wir haben dem Bauch des Tieres getrotzt. \ Wir haben gelernt, dass Ruhe nicht immer Frieden ist. \ Und die Normen und Begriffe \ von dem, was gerade ist, ist nicht immer nur Eis.“
| Processing

Wechseln wir nun also rüber, von Washington DC nach Kalifornien ins Silicon Valley und zu Timnit Gebru, die bis Anfang Dezember 2020 bei dem US-amerikanischen Technologieunternehmen Google angestellt war. Nach ihrer Entlassung von Google, auf die ich gleich zu sprechen kommen werde, gab es zwar viel Solidarität mit ihr innerhalb der Forschungsgemeinde, die größere ethische und kulturelle Debatte, wie Google beispielsweise seine eigens gesetzten Ethikrichtlinien ständig demontiert, blieb jedoch aus, z. B. wenn der Konzern das Gmail-Archiv als Trainingsdatensatz ihrer Hauseigenen KI-Sprachmodelle einsetzt. Nicht nur der Forscher Nguyên Hoang von Science4All sieht darin ein wahrlich schlechtes Vorzeichen für zukünftige Regulierungen.
Wie auf die persönlichen Informationen durch die diese riesigen Sprachmodelle trainiert wurden, wieder extrahiert werden können, zeigten uns Forscher Anfang Januar in ihrem Forschungspaper: „Extracting Training Data from Large Language Models.“
Sie demonstrierten darin einen Angriff auf das OpenAI-Sprachmodell GPT-2, der es ihnen ermöglichte, Hunderte von wortwörtlichen Textsequenzen aus den Trainingsdaten des Modells zu extrahieren. Diese extrahierten Beispiele enthielten (öffentliche) persönliche Informationen (Namen, Telefonnummern und E-Mail-Adressen), IRC-Konversationen, Programmiercode und 128-Bit-UUIDs.
Es ist inzwischen üblich geworden, große Sprachmodelle mit Milliarden von Parametern zu veröffentlichen (oder auch sie bewußt verschlossen zu halten), die auf privaten Datensätzen trainiert wurden. Das neue Sprachmodell aus dem Hause OpenAI heißt GPT-3 und wurde mit fast 500 Milliarden Wörtern aus dem Internet trainiert. Google scheint nun ein KI-Rennen zu beginnen, wahrscheinlich als Reaktion auf die begeisterten Kritiken von OpenAI oder eine wahrgenommene Bedrohung durch chinesische Unternehmen.

Wer an der KHM mit diesen Sprachmodellen wie z.B. GPT-3 künstlerisch experimentieren möchte, kann den Premium-Account für das Text-Adventure Game AI Dungeon nutzen oder eines der vielen KI-Sprachmodellinterfaces in der Experimentellen Informatik.
In den letzten Jahren entstanden zahlreiche künstlerische und literarische Arbeiten mit und durch transformerbasierten Sprachmodellen wie Googles BERT oder OpenAI’s GPT2, bzw. GPT-3.

Erwähnenswert sind hierbei die vier Bände »Poetisch denken«, die im letzten Jahr von dem digitalen Literaten, Autor und Literaturwissenschaftler Hannes Bajohr herausgegeben wurden. Als deep dreaming der Lyrik wurden diese mit GPT-2 geschriebenen und durch dies Sprachmodell generierten Bände bezeichnet.

Auch Mattis Kuhn arbeitete u.a. mit GPT-2 in seiner intelligenten Schreibmaschine. In seiner Diplomarbeit im letzten Herbst »Selbstgespräche mit einer KI« konstruierte, nutzte und reflektierte er eine auf sein Denken und Schreiben hin programmierte KI.
Mit GPT-3 wiederum erschien vor einigen Wochen ein imposantes maschinenliterarisches Werk: »Pharmako-AI«. Allado-McDowell hat mit und durch GPT-3 verfasstem Buch, ein erstaunlich positives Medienecho erhalten. Dieses wurde unterstützt von AutorInnen wie Bruce Sterling, Douglas Rushkoff, auch von Legacy Russell.
Blickt man hinter die breite Medienöffentlichkeit, so werden solche Werke wie »Pharmako-AI« innerhalb eines ganz bestimmten Kunstverständnisses getriggert und eines Kreativitätsbegriffs debattiert, der stark an den Kreativitätskult der 60er und 70er Jahre erinnert, der in großen Teilen der Kulturindustrie vorherrschte. Dieser kehrte den einst konzeptuellen Ansatz von Sol LeWitt „The idea becomes a machine that makes the art“ ins Gegenteilige um in „Die Maschine ist die Idee„. Nicht zuletzt zur Dienlichkeit der Kultivierung einer formalisierten Kreativität selbst.
IT-Unternehmen wie Google, Facebook, Microsoft, IBM, NVIDA u.s.w. versuchen derzeit in der KI-Kunst ein Revival dieser Art von Kreativität zu re-kultivieren, die auf dem derzeit exponentiell wachsenden Kreativ-Markt eine immer größere Nachfrage erfährt. Aufsteigende KI-KünstlerInnen werden von Start-Up Unternehmen, von Werbeagenturen, von Programmierern, von IT-Monopolisten, von KünstlerInnen in direkter Zusammenarbeit mit Forschungseinrichtungen, -Artist in Residencys im Fraunhofer-Institut, im Max-Planck-Institut etc. unterstützt und nicht selten veröffentlicht über eines von Googles zahlreichen Kulturförderungsprojekten. Creative Industries, dessen herausgebildeten KünstlerInnenindividuen sich selbst ihre eigenen Plattformen hierfür schufen, wie Allado-McDowell z.B., der das Artists + Machine Intelligence Programm in Google AI initiierte, eine seinen eigenen Bedürfnissen zugeschnitte AI-Artist Community.
Als einer der etablierten KünstlerInnen und LiteratInnen veröffentlichte der Schriftsteller Daniel Kehlmann vor einigen Tagen ein Buch, »Mein Algorithmus und ich« und zwar den Text einer Rede, die der Autor unlängst in Stuttgart hielt. Kehlmann berichtete dort von seiner Reise ins Silicon Valley, wo er auf Einladung von Open Austria das applikative Sprachmodell CTRL und dessen Schöpfer Bryan McCann kennenlernte.
Von der sogenannten Netzgemeinde wurde dieses Werk auf Grund seiner Technologie-Naivität, insbesondere aber für Kehlmanns Apologie des homo siliconvallensis kritisiert. Ein kurzer Einblick in Kehlmanns Erfahrungen im Silicon Valley findet sich in derselben, schon oben erwähnten WDR-Reihe, in der auch kurz die uns bekannte Maschinenlyrikerin Allison Parrish zu Wort kommt. Die von netzpolitik.org verfasste Kritik an Kehlmann ist die Verhandlung der uns vertrauten und in manchen Teilen auch lästigen aber stets notwendigen Frage, ob wir, als KünstlerInnen und LiteratInnen denn nun, – bewußt, oder auch nicht – unsere Kunst politisch machen wollen oder ob wir stattdessen Politische Kunst schaffen, Kunst im öffentlichen Interesse? Was heißt das eigentlich?
Tagtägliche künstlerisch-politische Entscheidungen, in der Auswahl unseres Materials, unserer Kunst-Werkzeuge, unserer “Kreativen Partner” wie manch Kritiker künstlerische Arbeiten mit und durch Künstlichen Intelligenzen bezeichnen.
Der Installationskünstler Thomas Hirschhorn verhandelte diese Frage in seinem Essay »BIC« und politisches Engagment wie folgt, wenn er schreibt, dass er “seine Arbeit als Künstler politisch mache, indem er sich Fragen politisch stelle” nicht etwa dadurch, dass er politische Fragen stelle und somit “eine politische Arbeit mache”. In diesem kurzen Essay von Hirschhorn ging es um eine Kritik u.a. an seiner Arbeit »Virus«, die mit Kugelschreibern der Marke “Bic” erstellt wurden. Die Firma “Bic” wurde damals finanziell von dem Holocaustleugner und rechtsextremen Politiker Jean-Marie Le Pen unterstützt.

Die Ethikforscherin Timnit Gebru verfasste Ende letzten Jahres gemeinsam mit Emily M. Bender ein Forschungspaper mit dem Titel »On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?, worauf hin ihr gekündigt wurde. Die beiden Forscherinnen argumentieren, dass der Trend zu immer größeren Modellen und immer mehr Trainingsdaten in der Computerlinguistik dazu führe, dass nicht nur massiv Ressourcen wie Strom für riesige Serverfarmen verbraucht würden, sondern auch dazu, dass KI-Modelle und Applikationen immer schlechter kontrollierbar werden und Minderheiten diskriminieren, ohne dass es den Entwicklerinnen und Entwicklern bewusst sei.
Auch die KI hinter Google Translate wurde auf einer riesigen Anzahl von Tokens (Wörtern) aus dem Internet trainiert und „lernte“ auf Basis dessen von einer natürlichen Sprache in die gewünschte andere zu übersetzen. Gebru machte u. a. darauf aufmerksam, dass es unmöglich ist, beispielsweise den Slang der Black Lives Matter Bewegung, die gerade eben versucht, in ihrer Kommunikation ein nichtbinäres, antisexistisches und antirassistisches Vokabular zu etablieren, sprich die bewußten Sprachgebräuche, die diesen neuen kulturellen Normen entsprechen, zu interpretieren. Die Bedeutungsvektoren dieser vortrainierter Sprachmodelle, gerade da sie mit einem möglichst breitgefächertem Textmaterial aus dem Internet trainiert wurden, sind nicht auf die Nuancen dieses Vokabulars abgestimmt.
Übersetzungsfragen nach kultureller und kollektiver Identität verschieben sich hierbei also auf eine andere, u. a. auf eine semiotische Ebene. Transferieren wir nun also die Fragen, die sich in den letzten Wochen bezüglich der Übersetzung von Amanda Gormans Gedicht „The Hill We Climb“ debattiert wurden, hin zu den uns alltäglich gewordenen Übersetzungsmaschinen von Konzernen wie Google oder dem Kölner Start-Up Unternehmen wie DeepL: “Müssen Übersetzer:innen immer aus der Gruppe der Originalverfasser:innen sein? Und wenn ja, welche Kategorien sind relevant? Können nur Schwarze die Texte von Schwarzen übersetzen? Nur Frauen die Texte von Frauen? Und wie ist es mit einem Text von einer Schwarzen Frau: ist ein Schwarzer Mann oder eine weiße Frau besser geeignet? Und vor allem: Wer entscheidet das?“
