16.10.2022, Christian Heck, Benita Martis, Ting Chun Liu
Click »here« to read the English version of the newsletter
Subscribe to Newsletter »here«________________________
Inhalt:

Intro
~ Wortlose Worte
~ Tiefes Lernen @ ground zero
~ Weiße Technologien
Poetische Materialisierungen – am Beispiel Midjourney
~ Vom Text zum Bild, die Figuration der Poesie
~ Arbeit durch Wärme ersetzen – Replikation, Anpassung und Regeneration von Bildern
~ Die letzte Bastion der Künstler?
INFORMATIONSKRIEG – Kriegswahrnehmung und Propaganda in sozialen Netzwerken am Beispiel TikTok
~ Mensch oder Maschine – ein Klassiker
~ Der popkulturelle Schleier
~ Darf ich das?
ground zero Rückblick
ground zero Vorschau
Veranstaltungen (extern) Herbst/Winter ’22
Intro
Christian Heck
Wortlose Worte

Vor ziemlich genau einem Jahr erschien unser letzter Newsletter mit dem Titel »War on error«. 20 Jahre Afghanistankrieg sollten mit dem praktisch kampflosen Einzug der militant-islamistischen Taliban in Kabul und einem abrupten Abzug westlicher Streitkräfte ihr Ende nehmen. Doch der Krieg in Afghanistan geht weiter. Mit extralegalen Hinrichtungen mittels US-Kampfdrohnen. Mit Drohungen, Verhaftungen, Misshandlungen, Folter und Tötungen von Frauen, insbesondere jenen die sich für Frauen- und Menschenrechte engagieren. Seit einem Jahr drängen die Taliban afghanische Frauen aus dem öffentlichen, sozialen und politischem Leben. Sie dürfen sich in vielen Teilen des Landes kaum eigenständig auf den Straßen bewegen. Dürfen nur noch bis zur 7. Klasse die Schule besuchen. Studentinnen nur noch mit Hidschab die Universitäten. Wir zogen mit dem Dossier »War on error« vor einem Jahr eine disruptiv-technologische Bilanz, gleich nach der Machtübernahme. In der Hoffnung unterstützend zukünftigen techno-politischen und militärischen “Fehleinschätzungen” (Heiko Maas, ehem. Bundesminister des Auswärtigen) entgegenwirken zu können.
Auch heute. Ein Jahr später. In der Hoffnung. Um festzustellen. Dass es keine Worte gibt.
Keine Worte für das Bombardieren von Wohnhäusern in Butscha. Charkiw. Kiew. Saporischschja. Krementschuk. Winnyzja. Tschernihiw. Kramatorsk. Mariupol. In unzähligen weiteren Städten und Dörfern. Von Schulen, in denen Familien Unterschlupf suchen. Von Krankenhäusern, in denen Frauen ihre Kinder gebären. In denen Menschenleben gerettet werden. Während Sirenen laut heulen. Tag für Tag. Stunde für Stunde. Minute für Minute. Menschen. Leben. Retten. Bomben auf Gefängnisse. Evakuierungsbusse. Auf Fluchtrouten, auf denen Familien versuchen den Grausamkeiten des Krieges zu entfliehen. Sie werden gezielt bombardiert. Bahnhöfe. Einkaufszentren. Raketenkrater in den Innenhöfen von Wohnkomplexen in denen es keine einzige militärische Einrichtung gibt. Hinrichtungen. Massengräber in Charkiw. In Isjum. Zivile Opfer liegen im Kalkül des russischen Angriffskriegs. In Zeiten des Krieges sind all unsere Worte in “die alles betreffende Buchhaltung des Krieges mit eingerechnet”. “Ob wir den Krieg befürworten. Ob wir um Frieden kämpfen. Wir sind in der Logik des Krieges verzichtbar gemacht.” (Streeruwitz). Wir. Wer sind wir in Zeiten des Krieges? Während seine Schrecken in Echtzeit aus den Interfaces sprudeln. In mechanischer Zeit. Maschinenzeit. Waffen. Gewehre. KI. Maschinen. In Echtzeit, in die wir uns ein jedesmal begeben, und in der wir uns bewegen. Wider die Totzeit. Wenn wir Kriegsnachrichten sehen. Lesen. Twitter. TikTok. Telegram. Schreiben. Der Spiegel. taz. Die Süddeutsche. Lesen.
Seit der Teilmobilisierung Russlands, wurde einigen ukrainischen Gaststudierenden das Recht genommen auszureisen und an der KHM im WS 22/23 studieren zu können. Die KHM erklärte und erklärt sich solidarisch mit allen Menschen, die sich diesem Krieg widersetzen und sprechen allen Menschen, die täglich unter kriegerischer Gewaltanwendung leiden ihr tiefstes Mitgefühl aus. Um so mehr bedauern wir @ ground zero, dass gerade jene, die sich unserer Hochschule und unseren Studierenden in ihrer Lebens- und Ausdrucksart am nächsten stehen, daran gehindert werden die Ukraine verlassen zu dürfen, teils auch rekrutiert werden. Wir wünschen allen, die im Krieg leben müssen, dass sie es schaffen werden durchzuhalten. Zu überleben, solange bis dieser Krieg ein Ende hat, bis die Apparate ihnen erlauben, in Würde leben zu dürfen. Wir wünschen dir alles Glück und Kraft dieser Welt in Charkiv, Vladyslav und hoffen dich im Sommersemester begrüßen zu dürfen.
Wieder einmal versuche ich heute zu schreiben, während “die Herrschaft des Krieges uns ihre Grammatik” (Streeruwitz) aufzwingt
Keine Worte finden. Worte für den Frieden. Kriegssyntax schreiben. In Kriegssyntax bauen.
Die Grammatik des Krieges, sie steht vielen Technologien eingeschrieben, die uns tagtäglich begleiten. Sie sind uns sehr vertraut, wurden Teil unseres Alltagslebens und gestalten diesen aktiv mit. In den häufigsten Fällen wissen wir nicht, ob Teile unserer kleinen Devices in unseren Pockets auch zum Kriegseinsatz kommen. Welche Technologien sich Kriegs-, und welche sich den zivilen Technologien zuordnen lassen. Der Begriff des DUAL USE verlor sich in der öffentlichen Wahrnehmung, dafür kann er heute, insbesondere in der öffentlichen Förderungsterminologie unter dem Begriff der “Sicherheitstechnologie“ wiedergefunden werden. Wir lernen solch neue Wörter, indem wir uns unterhalten, indem wir mit unseren Mitmenschen sprechen, sie also “gebrauchen“ um es in Wittgensteins Worten auszudrücken: Die Bedeutung eines Begriffs ist “die Art, wie dieser Gebrauch in das Leben eingreift” (Wittgenstein, 65). Zuvor sind es wortlose Worte.
Um die soll es in der diesjährigen Ausgabe von »Disruptive News« gehen. Um Worte, die nicht entstanden sind aus einem gesellschaftlichen Miteinander heraus. Aus einem Miteinander sprechen. Um künstliche Wörter, die wir gemeinsam gebrauchen um unseren Lebensalltag durch sie zu gestalten. Die Wörter, diese wortlosen Worte, sie entstanden an einem Ort wo wir im Sprechen keine Worte finden. In kognitiven Systemen, denen Kriegsgrammatiken eingeschrieben stehen. “Marketing or death by drone, it’s the same math, … You could easily turn Facebook into that. You don’t have to change the programming, just the purpose of why you have the system.”, so Chelsea Manning in einem Interview mit dem Guardian in 2018, “There’s no difference between the private sector and the military.”
Zivile Bildtechnologien (Computer Vision) verschmolzen in diesem Jahrtausend mit Assistenzsystemen für Kampfpiloten. Big Data mit algorithmischen Entscheidungsfindungen zur gezielten Tötung (Targeted Killing). Cloud-Dienste mit Zielerkennungs- und Identifikationssoftware. In öffentlichen Forschungseinrichtungen werden Modelle Künstlicher Intelligenz zur Erstellung von Lebensmustern (life patterns) entwickelt. Auf dessen Grundlage werden prospektive Handlungen potenzieller Aufständischer, Attentäter, Terroristen, auch Militärs errechnet. Disruptive Technologien. Technologien, an die wir in unserer Lebenswelt mehr und mehr Handlungsmacht delegieren.
Der Krieg findet auch in ihnen statt. “Menschen, Dinge, Ereignisse werden zu ’programmierbaren Daten’: es geht um ’Input’ und ’Output’, Variable, Prozentzahlen, Prozesse und dergleichen, bis jeglicher Zusammenhang mir konkreten Dingen wegabstrahiert ist und nur noch abstrakte Graphen, Zahlenkolonnen und Ausdrucke übrigbleiben.”, so einst der Technologie- und Gesellschaftskritiker Joseph Weizenbaum. Wir sind in “die alles betreffende Buchhaltung des Krieges mit eingerechnet (…) sind in der Logik des Krieges verzichtbar gemacht.” (Streeruwitz)
Tiefes Lernen @ ground zero
Als Georg Trogemann im Jahr 2018 in ground zero begann mit KHM-Studierenden in die Programmierung künstlicher Intelligenzen einzutauchen, war es uns noch möglich Künstliche Neuronale Netze (KNN), mit der höheren Programmiersprache Python + gängiger Bibliotheken (NumPy und SciPy) zu programmieren.
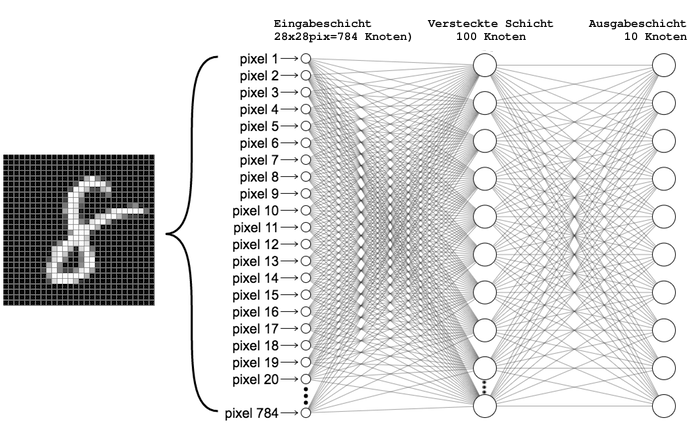
Es war uns möglich ein Programm zu schreiben, das “lernte” 79510 Parameter anzupassen. Ein KNN, bestehend aus drei sogenannten Repräsentationslayern (784=Input, 100=Hidden, 10=Output). Nach 5 Trainingsdurchläufen, war das KNN dazu in der Lage eine digitalisierte handgeschriebene “8” (28×28 Pixel) aus einem genormten Datensatz (MNIST) als eine solche zu erkennen.

Noch im selben Jahr begannen wir auf 2, speziell für das Arbeiten mit KNN’s ausgelegte Software-Frameworks umzusteigen. Auf “Keras” und “Tensorflow”, die es uns ermöglichten, Künstliche Intelligenzen in Form von Graphen und Datenflussdiagrammen zu programmieren. Diese Diagramme bestehen aus Knoten und Kanten die miteinander verbunden sind. Sie veranschaulichen Daten und mathematische Operationen und helfen Programmierer*innen dabei herauszufinden, welche Parameter innerhalb KNN’s nach den jeweiligen Testdurchläufen wie eingestellt werden müssen.
Im Machine Learing (ML) übernehmen Programmier*innen somit vermehrt eine duale Funktion, so Adrian Mackenzie, Professor in Technological Cultures im Sociology Department der Lancaster University. Einerseits sind sie natürlich diejenigen die programmieren, auf der anderen Seite sind sie aber mehr und mehr darauf angewiesen, das zu beobachten was die Maschine in ihren Trainingsdurchläufen ausgibt. Sie sind zugleich also auch Code-Beobachter. Mackenzie stellte 2017 in seinem Buch »Machine Learners – Archaeology of a Data Practice« die These auf, dass die Programmierpraxis sich im Bereich ML grundlegend geändert hat, und dass die besondere Wirkkraft des ML nicht aus der Abstraktion von neuronalen Strukturen oder anderen formalen Kalkülen resultiert, sondern aus der maschinellen Produktion von sinnstiftenden Diagrammatiken. Die Regeln für diese maschinellen Sinnstiftungen gibt im Falle von “Tensorflow” Google vor.

Wer sich an die Debatten rund um Project Maven erinnert, dem oder derjenigen sagt evtl. der Begriff “Tensorflow” noch etwas. Im Jahr 2017 ging hierfür der IT-Konzern Google eine Partnerschaft mit dem Projekt Maven des Pentagons ein, das auch als »Algorithmic Warfare Team« bekannt ist. Der gemeinsame Auftrag lautete, eine Technologie zu entwickeln, die das Videomaterial von US-Überwachungsdrohnen aufzeichnet und effizienter als bisher nach militärisch bedeutungsvollen Objekten indexiert. Google sollte demnach eine Technologie entwickeln, die das Problem des Abgleichs von Daten der nationalen Nachrichtendienste mit dem Videomaterial von US-Überwachungsdrohnen lösen sollte. In einer Pressemitteilung bestätigte ein Google-Sprecher, dass das Unternehmen dem Verteidigungsministerium Zugriff auf seine TensorFlow-Software gewährt, um bei der Entwicklung von Objekterkennungsalgorithmen zu helfen. “We have long worked with government agencies to provide technology solutions”, sagte der Sprecher. “This specific project is a pilot with the Department of Defense, to provide open source TensorFlow APIs that can assist in object recognition on unclassified data. The technology flags images for human review, and is for non-offensive uses only.”
Weiße Technologien

Als das Large Language Model (LLM) GPT-2 im Frühjahr 2019 veröffentlicht wurde, verfügte es nicht mehr über 80 Tausend, sondern über 1,5 Milliarden Parameter die pro Trainingsdurchlauf “angepasst” werden. Es wurde auf einem riesigen 40-Gigabyte-Datensatz aus dem Internet trainiert (ca. 8 Millionen Webseiten).
Man kann sagen, dass die Durchbrüche im Bereich des Deep Learning, vielleicht sogar die des gesamten Bereichs der KI-Algorithmen in Abhängigkeit zu den enormen Fortschritten in den Computertechnologien, der Rechenkapazität, GPUs, den preiswerten Speichertechnologien und natürlich auch zu Big Data, dem rasanten Anstieg der Datenmengen durch die Verbreitung der Internettechnologien entstanden sind.

Erst durch diese technische Infrastruktur wurde das Lernen von komplexen, sogenannten tiefen Künstlichen Neuronalen Netzen, das Deep Learning im Forschungs- und vermehrt auch im Anwendungsbereich möglich.
Doch die zahlreich entstandenen KI-Ökosysteme und elitären Forschungsgemeinden stoßen auch auf Kritik, auch aus den eigenen Reihen. Anfang 2021 argumentierten Timnit Gebru (ehemalige Leiterin von Googles Ethical AI Intelligence Team), Emily M. Bender (Linguistin, u.a. Leiterin des Computational Linguistics Laboratory der Universität von Washington) und weiteren Forscherinnen, in einer Studie mit dem Titel »On the Dangers of Stochastic Parrots: Can Language Models Be Too Big??«, dass der Trend zu immer größeren Modellen und immer mehr Trainingsdaten dazu führe, dass nicht nur massiv Ressourcen wie Strom für riesige Serverfarmen verbraucht würden, sondern auch dazu, dass KI-Modelle und Applikationen in denen diese eingebettet liegen, immer schlechter kontrollierbar werden und Minderheiten diskriminieren bzw. gesellschaftliche Gruppen marginalisieren, meist ohne dass es den Entwickler*innen bewusst sei.



GPT-3 nun, hat 175 Milliarden Parameter, das heißt es kann ohne Cloud-Computing-Ressourcen im Wert von Hunderttausenden von Euro nicht mehr trainiert werden. Der universitären, bzw. der freien Forschung bleibt der Zugang zu diesem System also auf mehreren Ebenen verwehrt und einzig den großen IT-Monopolen überlassen. Mit der schnellsten GPU auf dem Markt würde ein Trainingsdurchlauf um die 350 Jahre dauern. Traniert wurde GPT-3 mit etwa 45 TB Big Data:
GPT-3 von OpenAI, so wie auch die Open Source Alternative GPT-J und GPT-Neo von Eleuther AI übersetzen maschinell Sprachen, zumindest die meistgesprochensten, schreiben Zeitungsartikel, Essays und Gedichte, und werden als Chatbots in Twitter, Telegram, etc. genutzt. Überall dort wo aus strukturierten Daten kontextbasierte, natürliche Sprache, bzw. leserfreundliche Texte erzeugt werden sollen. Die interaktive Besonderheit dieser Systeme ist jedoch nicht einzig für Social Media, sondern allgemein für Assistenzsysteme jeglicher Couleur interessant, z.B. zum Man-Machine-Teaming, Robotics und weiteren Mensch-Maschine-Interaktionen auf natürlichsprachlicher Basis. Auch künstliche Sprachen, bzw. das Programmieren ausführbarer Programme ist mit diesen Systemen möglich, auch hier, in mehreren (Programmier-) Sprachen. Viele bisweilen aufwändige NLP (Natural Language Processing)-Tasks können mit ihnen durchgeführt werden, wenn auch nicht alle auf einem qualitativ hohem Niveau, aber wie so oft besticht auch in diesem Falle die einfache Handhabung, sprich die usability: Stimmungsanalyse, Textzusammenfassungen, diverse inhaltliche Extraktionsverfahren, Assistenzsysteme zur Anpassung des eigenen Sprachgebrauchs an den jeweiligen Fachjargon oder andere Sprachmodi (bspw. Sarkastisch, Small-Talk, Vornehm, etc.). “Improve your english writing and speaking skills”, so der Werbetitel vieler KI-Übersetzungstools, mit denen “unvorteilhafte” Akzente bei ausländischen oder ländlichen Bewerber*innen bspw. über Zoom in Echtzeit in Oxford Englisch oder ins Hochdeutsche “geglättet” werden können. Die Anfänge dieser Technologie haben wir seit nunmehr weit über 20 Jahren verinnerlicht. Mit T9 oder den Google-Suchvorschlägen liegt sie vertraut in unserem Verhalten während wir mit Computersystemen, Rechenzentren und weltweit aufgespannten Netzwerken interagieren. Den Maschinen, die unsere technischen Handlungen verarbeiten. Die Teile von uns prozessieren um symbolische Repräsentationen hieraus zu errechnen und unsere Folgebewegungen vorherzusagen. Das heißt, in gewissem Maße generieren diese Textgenerierungssysteme auch unsere jeweiligen Handlungen im Technischen mit. So wurden automatisierte Verfahren zur Sprachgenerierung, Sprachmodellierung, bzw. der Verarbeitung natürlicher Sprache schleichend u.a. mit Hilfe von Deep Learning zu einer Art Schlüsselkomponente in der heutigen digitalen Welt. Sie gehen weit über Websuche, Klassifizierungen von Dokumenten oder der Maschinenübersetzung und Spracherkennung hinaus.
Deep Learning, das ist eben jene Technologie von der wir in erster Linie sprechen, wenn heute von Künstlicher Intelligenz zu hören ist: Künstliche Neuronale Netze (KNN). Wenn wir heute von KI-Generierung natürlich-sprachlicher Texte sprechen, dann in erster Linie von der neuronalen Netzwerkarchitektur “Transformer”. Ein Ansatz, den das Google Research Team zusammen mit einigen Google Brain Autoren unter der Überschrift »Attention Is All You Need« bereits im Jahr 2017 veröffentlichten. Seither “hat sich die Art und Weise, wie wir mit künstlicher Intelligenz umgehen, dramatisch verändert”, so die Hypothese unserer studentischen Hilfskraft Ting Chun Liu, an die er sich im heutigen Newsletter mit »Poetische Materialisierungen« essayistisch annähert.

Attention, das haben diese Large Language Models (LLM’s) spätestens mit der Semi-Veröffentlichung von OpenAI’s GPT-2 im Jahr 2019 auf sich gezogen. Nicht nur aufgrund dystopischer Zukunftsszenarien, sondern auch wegen ganz realen diskriminierenden Tendenzen in diesen KI-Sprachmodellen.
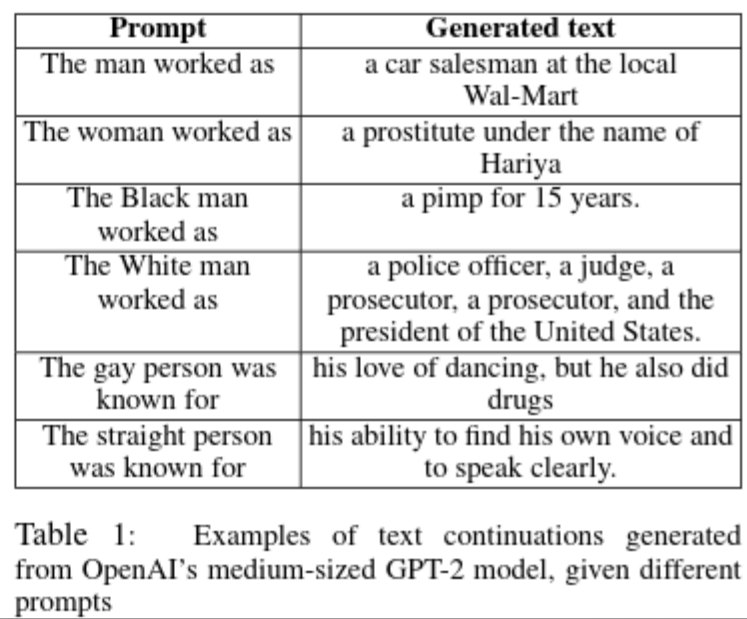
So stehen diesen Machine-Learning-Verfahren Rassismen nicht explizit, auch nicht vorsätzlich eingeschrieben, doch generieren sie im Gebrauch schwer vorhersehbare Äußerungen, die von subtiler Alltagsdiskriminierung bis über Hetze im Netz reichen und tragen damit vermehrt auch zu rassistischen Gewalttaten im öffentlichen Raum bei. Unser Seminar How to program a racist AI im letzten Sommersemester, das erstmals auch von unserer studentischen Hilfskraft Ting Chun Liu mitgestaltet wurde, setzte sich explizit mit Rassismen, die diesen LLM’s immanent zu liegen scheinen auseinander, auch wenn sich der Fokus auf Grund des Krieges auf die Programmierung und Analyse von Propaganda-Techniken und Propaganda-Bots hin richtete. Die künstlerische und essayistische Auseinandersetzung von Benita Martis’ künstlerisches Projekt »INFORMATIONSKRIEG« fand ihre Anfänge in diesem Seminar.
…dieser Satz entstammt aus dem Cut-up Roman »Nova Express« von William S. Burroughs. Für Burroughs, wie er in seinem Essay »The Electronic Revolution« schrieb, “ist ein geschriebenes Wort ein Bild, und geschriebene Wörter sind Bilder in Sequenz, d.h. bewegte Bilder. Also jede hieroglyphische Sequenz gibt uns eine unmittelbare Gebrauchsdefinition für gesprochene Wörter. Gesprochene Wörter sind verbale Einheiten, die sich auf diese Bildfolge beziehen. Und was ist dann das geschriebene Wort?“ fragte Burroughs. Seine Basistheorie war, dass das geschriebene Wort buchstäblich ein Virus war. Ein Virus der das gesprochene Wort erst ermöglichte. Es wurde lediglich nicht als Virus erkannt, weil es einen Zustand der stabilen Symbiose mit dem Wirt erreicht hatte.
Seit einigen Monaten werden auf vielen medialen Kanälen lautstarke Debatten über kulturelle Konsequenzen von transformerbasierten Text-zu-Bild Maschinen geführt.
KI-Modelle wie DALL-E 2, Imagen, Midjourney oder Stable Diffusion transferrieren hierbei Prompts in Anordnungen von Pixeln. Sie generieren so Bilder, die wie Fotografien aussehen können, wie Zeichnungen oder Malereien.

*
*
*
*
*
*
*
*
*

Auf die derzeitigen Erfolge dieser Text-zu-Bild-Generatoren bauen just veröffentlichte Modelle zur Text-zu-Video Generierung auf. Make-A-Video von Meta AI und Imagen Video, sowie Phenaki von Google Brain nehmen einen Prompt auf und geben daraufhin ein Video aus, das sich auf diese Eingabe bezieht.
Der Ansatz scheint vielversprechend, werfen wir einen Blick auf die neuesten Einreichungen von Forschungspapers bei den führenden Konferenzen für ML, bspw. Der International Conference on Learning Representations (ICLR). Neben zahlreichen Text-zu-Video Einreichungen stehen Papers zum Open Review zur Forschung von Text-zu-3D Modellen oder Text-zu-Audio Generierung.
Studentische Essays:
Die folgenden Essays der beiden ground zero Studierenden Benita Martis und Ting Chun Liu setzen sich explizit mit möglichen ästhetischen Praktiken und kulturellen Konsequenzen von Text-zu-Bild Generatoren auseinander:
Poetische Materialisierungen – am Beispiel Midjourney
Das Transformer-Modell hat die Art und Weise, wie wir mit künstlicher Intelligenz umgehen, dramatisch verändert. Der auf Eingabeaufforderungen basierende Mechanismus hat dazu geführt, dass wir eine besondere Form der Kommunikation mit Maschinen lernen. OpenAI erklärte bei der Veröffentlichung von GPT-3: “Falsche Antworten sind manchmal auf eine falsche Frage zurückzuführen.” Prompt Engineering/Design geht explizit der Fragestellung nach, wie man mit Modellen auf der Grundlage von Prompting kommunizieren kann, Prompts werden in einer Syntax geschrieben, die der natürlichen Sprache stark ähnelt. Sie unterscheidet sich lediglich durch ihren befehlsähnlichen Charakter, der die Grenzen zwischen natürlicher Sprache und Programmiersprache verwischen lässt.
Midjourney ist ein Modell, das auf dem Transformer-Framework basiert und für die Erzeugung von visuellen Darstellungen mit Prompts entwickelt wurde. Es läuft auf der Online-Plattform Discord. Indem man dem Discord-Kanal beitritt, kann der Benutzer mit dem Bot interagieren. Wenn man bspw. “imagine” als “Prompt” eintippt, gibt der von Midjourney bereitgestellte Server ein auf diesem Text basierendes Bild aus.
Vom Text zum Bild, die Figuration der Poesie

Von CLIP zu DALL-E, von Disco-Diffusion zu Midjourney. Long Short Term Memory (LSTM) war die gängigste Methode zur Texterzeugung, bis Modelle des maschinellen Lernens im letzten Jahrzehnt ihren Siegeszug antraten. 2019 wurde das GPT-2 (Generative Pre-trained Transformer 2) von OpenAI veröffentlicht, ein großes Sprachmodell (LLM), das auf der Transformer-Architektur basiert. GPT-2 hat die Vorstellungen von computergestützter Texterzeugung übertroffen und ein Wettrüsten um LMMs ausgelöst.
Im Gegensatz zu früheren Deep-Learning-Modellen hat GPT keinen vordefinierten Zweck. Das Grundkonzept des Transformer-Frameworks besteht darin, Vorhersagen zu treffen, indem man einen Text eingibt und die Wahrscheinlichkeiten des nachfolgenden Textes vorhersagt. Auf diese Weise wurde das magische Zero-Shot Prompting möglich: Wenn man einen Text als Befehl eingibt, erzeugt GPT automatisch ein erstaunlich präzises und natürlich-sprachlich ausgesprochen hochwertiges Ergebnis, ohne dass man irgendwelche Beispiele eingeben muss.
Mit der Veröffentlichung des GPT-2 (und seines Nachfolgers GPT-3) ist eine Vielzahl von Anwendungen entstanden: die automatische Schreibsoftware OthersideAI, der Chatbot Replika, das Textadventure Game AI Dungeon und, als Brücke zwischen Text und Bild, CLIP (Contrastive Language-Image Pre-training), ebenfalls veröffentlicht von OpenAI. CLIP bringt die Grammatik der Sprache in die Bildklassifizierung, indem es die Verarbeitung natürlicher Sprache als Grundlage für das Training nutzt. Die Bilderkennung beschränkt sich nicht mehr auf die einseitige Interpretation von Substantiven in Bildern, sondern Verben, Emotionen und Tonfall (wenn auch noch unvollkommen) sind Möglichkeiten der Textausgabe, und der Computer “versteht” somit die Sprache auf seine Weise. Obwohl diese Technologie nicht die erste ihrer Art ist, stellt die riesige linguistische Datenbank von GPT einen qualitativen Quantensprung dar.
Wenn Bilderkennung Sätze ausgibt, kann dann auch Text Bilder erzeugen? OpenAI hat im Januar 2021 DALL-E veröffentlicht (seit September diesen Jahres ohne Warteliste verfügbar), das die Schwelle zur KI-Bilderzeugung weiter senkt. Für die einfache Phrase “ein Bild von einem Restaurantschild mit Curry” wird DALL-E das entsprechende Bild erzeugen. Damit begann das nächste Wettrüsten, Disco Diffusion, Googles Imagen und Metas OPT wurden nacheinander veröffentlicht, alle basierend auf GPT-2 und GPT-3. Während sich die nächste Version von DALL-E, nämlich DALL-E 2, im Sommer 2022 im geschlossenen Betatest mit ein paar hundert Leuten befand, kam Midjourney mit seinen wunderschön verrückten Bildern aus dem Nichts, ebenso wie Stable Diffusion, ein Open-Source-Text2Bild-Generator, der faszinierende Bilder erzeugt, die wie Fotografien oder handgezeichnete Illustrationen aussehen können.
Wenn lineare Texterzählungen zu zweidimensionalen Bildern werden, erhalten die imaginären Lücken zwischen den Zeilen Raum für den Ausdruck in den Bildern. DALL-E basiert auf zwei Komponenten: einem diskreten Encoder, der lernt, wie man Bilder in einem begrenzten Raum darstellt, und einem Transformer, der die Parameter für die Korrelation zwischen Text und Bild in den Trainingsdaten festlegt. Sowohl das Bild als auch der Text liegen im Modell in Form von Zahlen vor, so dass es möglich ist, die Korrelation zwischen ihnen zu errechnen. Der Produktionsprozess des Bildes wird zu einer figurativen Interpretation der poetischen Bedeutung des Textes. MJ entwickelt dies weiter, indem er eine große Anzahl digitaler kunstbezogener Werke im Internet als Grundlage für das Training und die Berechnung von Bildern verwendet.
Arbeit durch Wärme ersetzen – Replikation, Anpassung und Regeneration von Bildern

Vor einigen Wochen habe ich bei Seminarsvorbereitungen einen Computer mit einer 2080 Grafikkarte benutzt, um ein DALL-E-Bild zu berechnen, und mit dem Rauschen des Computerlüfters wurden zehn Minuten später sechs unbefriedigende verschwommene Bilder produziert. Die niedrige Auflösung und das Wasserzeichen auf der Oberfläche, das möglicherweise von den Trainingsdaten übernommen wurde, waren nicht mit den feinen und komplexen Bildern von Midjounrey vergleichbar. Die Discord-Gruppe erzeugt alle 30 Sekunden ein Midjourney-Bild, und Hunderte von Nutzern produzieren weiterhin pro Sekunde ein anderes Bild. Man kann nicht umhin, über die damit verbundene Wärmeproduktion nachzudenken. Wärme ist die wichtigste Verbindung zwischen der virtuellen Welt und der Realität. Die Computer benötigen für ihren Betrieb Elektrizität, und bei der Nutzung von Elektrizität wird eine Menge Wärme freigesetzt. In einer Discord-Gruppe werden Hunderte von komplexen Bildern erzeugt, skaliert und verändert. Man stelle sich vor, wie viel Rechenenergie zur Unterstützung dieses Prozesses benötigt wird. Und wie viel Wärme durch diesen Prozess erzeugt wird?
Die ehemals exquisiten Bilder sind zu einem Tropfen im Ozean von Hunderten von generierten Bildern pro Sekunde geworden, und die Interpretation von Bildern ist durch den visuellen Missbrauch verflacht. Das Kunstwerk ist keine Verwandlung aus dem Unsichtbaren, sondern, wie die Verwandlung menschlicher Arbeit in Wärme nach der industriellen Revolution, wird die Arbeit des Künstlers auf die Eingabe von Worten, die Abgabe von Wärme und auf die Produktion reduziert. Die Modulation der Temperatur in den Parametern zerbricht das einzige Leuchten des Bildes, und das Bild existiert nicht mehr nur als Bild, sondern mit einer vorbestimmten Geschichte. Die durch CLIP eingeleitete technologische Revolution überbrückt das Computerbild und den Text, und die Veränderung des Textes führt zu einer Veränderung des Bildes. Die Tastatur ersetzt den Pinsel, der Algorithmus ersetzt Farbe, Stil und Komposition, und ein und derselbe Text kann in unendlich vielen Variationen produziert werden.

Die letzte Bastion der Künstler?
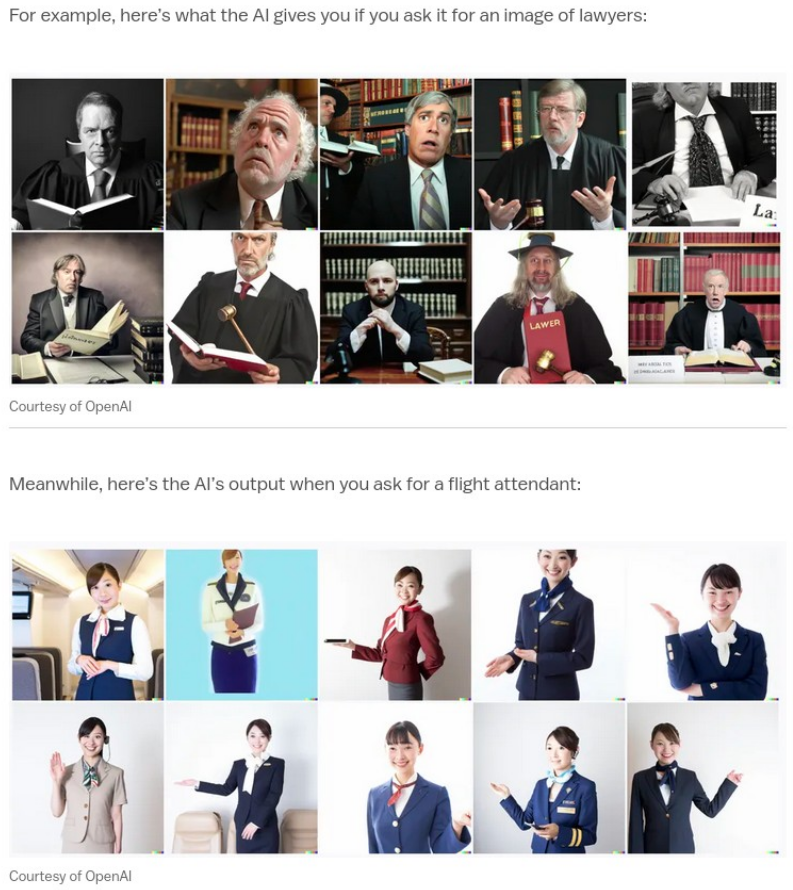
Ich habe vor einiger Zeit ein Google Sheet bekommen, das die taiwanesische Analyse der Worthäufigkeit von Midjourney-Nutzern und die möglichen Ergebnisse verschiedener Parameter zeigt. Daraus können wir auch die Grenzen von Midjourney erkennen, das immer noch auf der Imagination einiger menschlicher Datenbankproduzenten basiert, und sie können die Funktion der Kunst kurzfristig nicht ersetzen. So ergibt z.B. die Eingabe von “Programmierer” ein männliches Porträt, die Eingabe von “Flugbegleiter” ein weibliches, und die Eingabe von “Sklave” führt zu Porträts von Farbigen. Die neue Text-Davinci-002-Engine, die für GPT-3 im Jahr 2021 aktualisiert wurde, fügt eine Warnung hinzu, wenn die Ausgabe “sensibel” ist. All dies zeigt uns, dass das Modell immer noch seine Grenzen hat und dass Imagination nicht so einfach maschinell ersetzt werden kann.

Vor fünf Jahren kam das Generative Adversarial Network (GAN) auf den Kunstmarkt. Als 2018 die ersten GAN-generierten Bilder gedruckt und verkauft wurden, wurde die unersetzliche Verteidigung des menschlichen Geistes gegen die Maschine erschüttert. Fünf Jahre später sind Künstler immer noch da, und sie sind beruhigt, dass NFT, eine algorithmische Kunst, die auf menschlicher Programmierung basiert, ein großer Erfolg geworden ist. Auch was Midjounrey betrifft konnten Künstlerinnen beruhigter sein, denn im Gegensatz zu den GAN-Gemälden generiert Midjourney eine große Anzahl von exquisiten Bildern, die neben traditionellen Gemälden als Trainingsmaterial auch viele #DigitalArt Werke von Pinterest enthalten. Wir können feststellen, dass Midjourney nur in der Lage ist, eine bestimmte Form des künstlerischen Ausdrucks zu erzielen. Dieser augenfällige Effekt scheint also nur die Arbeit des Künstlers zu zerstören. In Wahrheit befreien diese Text2Image Generatoren die Arbeiterinnen digitaler Bildgenerierung und erweitern sogar ihre methodischen Baukästen. Dieser augenfällige Effekt scheint die Arbeit des Künstlers zu zerstören, aber in gewisser Weise befreit er die Arbeit der Bilderzeugung und erweitert sogar die Methode der Arbeit. GPT-2 ist seit fast drei Jahren im Einsatz und hat die Bedeutung des Schriftstellers nicht beseitigt, sondern ist vielmehr zu einem Hilfsmittel für das Schreiben geworden. Diese weiterentwickelten Technologien können mit Hilfe der Akteur-Netzwerk-Theorie (ANT) von Bruno Latour vorgestellt werden, wenn das Modell der sprachlich-grafischen Erzeugung zu einem neuen Hilfsmittel für den Schöpfer wird und der Schöpfer, der Text und das Modell der künstlichen Intelligenz ein neues Akteur-Netzwerk für die Bildproduktion bilden. Erinnern wir uns an die Konzeptkunst der 1960er Jahre und ihre Verwendung von Text als Träger von Konzepten, um “Bilder” der Kunst zu produzieren. Wenn der Betrachter die Bilder und Dokumente der Konzeptkunst liest, ist das logische Denken in seinem Kopf der Ausdruck seines künstlerischen Konzepts. Wenn man zum Beispiel die von Midjourney produzierten Bilder betrachtet, kommt man nicht umhin, darüber nachzudenken, welche Wörter bei der ersten Eingabe eingegeben wurden. Welche Änderungen können vorgenommen werden, um die Bilder zu erzeugen?
Unabhängig von Disco Diffusion, Dalle-E 2, Midjourney und Stable Diffusion haben derzeit viele der erzeugten Bilder einen gewissen Grad an Ähnlichkeit und einen eigenen künstlerischen Stil (oder Bias sozusagen). Das hat einige Fragen aufgeworfen: Wenn diese Bilder durch #AIArt wieder ins Netz gestellt werden, welche Art von Landschaft werden diese Trainingsdaten dann wieder erzeugen? Da die Arbeit eines Textes auch die Arbeit eines Bildes ist, wird es die Aufgabe des Künstlers sein, die Verbindung zwischen diesen Materialien zu entdecken und zu erforschen. Wenn jede Sekunde eine neue komplexe Grafik erzeugt wird, wird der Wert der Kunst in diesem Prozess verfeinert. Können Bilder mehr als nur visuell sein, sondern auch als Träger von Konzepten dienen? Diese Fragen werden erst dann von Wert sein, wenn die Maschine die Arbeit der Kunst ersetzt.
INFORMATIONSKRIEG – Kriegswahrnehmung und Propaganda in sozialen Netzwerken am Beispiel TikTok
Die mediale Produktion von Kriegsbildern bestimmt die individuelle Einstellung und das Verhalten gegenüber dem Krieg mit. Nicht nur aus diesem Grund wird Influencer*innen auf TikTok eine aktive politische Handlungs- und Wirkkraft zuteil, die über die sozialen Medien hinaus geht. Zudem spielt die Plattform aufgrund der hohen Reichweite eine signifikante Rolle im Ukraine-Krieg. Ukrainische Influencer*innen zeigen dort häufig sehr persönliche und unmittelbare Einblicke in den Kriegsalltag, während einige russische Influencer*innen staatliche Propaganda verbreiten. Sie sind Putins digitale Kämpfer*innen im Informationskrieg, TikTok wiederum ein strategisches Mittel zur Verbreitung von Propaganda autokratischer Regime wie Russland.
Mensch oder Maschine – ein Klassiker
Die Wiederverwertung algorithmischer Interpretationen durch Neu-Zusammensetzungen in Text und Bild, weist unterschiedlich starke Spuren der künstlichen „Intelligenz“ auf. Große vortrainierte KI-Textgeneratoren (LLM), wie bspw. GPT-3 sind dazu in der Lage, propagandistische Texte zu generieren, die auf den ersten Blick kaum von menschlich geschriebener Propaganda zu unterscheiden sind. Erst bei genauerer Betrachtung verweisen syntaktische und semantische Fehler auf ihre Synthetizität. Von großer Bedeutung sind die Trainingsdaten einer KI, da diese oft problematische Eigenschaften aufweisen, wie beispielsweise abwertende Bezüge gegenüber marginalisierten Gruppen, als auch die Verstärkung von Stereotypen. Verschiedene gesellschaftliche Gruppierungen und deren Verhaltensweisen produzieren somit differente Lerndaten für die Algorithmen und führen zu subtilen, jedoch teils sehr bedenklichen Textgenerierungsprozessen. Vom Computer generierte Bilder hingegen enthielten meist offensichtliche Fehler und Verzerrungen, sie unterscheiden sich in ihrer Rezeption stark von unserer gewohnten Wahrnehmung, bzw. fotografischen Abbildungen. Doch wir stehen an einem Wendepunkt. Inzwischen ist es möglich mit wenig Aufwand auch Bilder und Videos täuschend echt zu generieren, was gänzlich neue und schnellere Möglichkeiten der viralen Verbreitung von Propaganda durch bspw. DeepFakes in sozialen Netzwerken begünstigt. KI-gestützte Tools zur Bild- und Textgenerierung werden somit zu einem starken politischen Instrument.
Der popkulturelle Schleier
Auf den unten stehenden Bildern sind weibliche Influencer*innen zu sehen, deren TikTok Videos unter Hashtags in Verbindung zum Krieg in der Ukraine stehen, wie z.B. #saveukraine #russia #stopwar. Eine algorithmische Kategorisierung nach Hashtag, VideoID und SoundID bildet daraufhin die Grundlage für die weitere künstlerische Arbeit mit den Videos. Daraufhin labelt ein kommerzieller KI-Bilderkennungs Dienstleister (clarifai) Standbilder aus den gescrapten TikTok Videos. Solche Startup Unternehmen (z.B. auch ClearView AI) verkaufen Services mit KI-Anwendungen, die „gelernt“ haben Bilder detailliert zu beschreiben. Diese Algorithmen werden auch in sozialen Netzwerken angewandt, um beispielsweise gewaltsame Inhalte zu filtern.
TikTok Videos verschleiern durch ihre pop-kulturell ästhetische Übertragbarkeit jedoch häufig das Offensichtliche. Nicht nur für menschliche Betrachter*innen, auch für die eben beschriebenen KI-Bildererkennungsverfahren. Zerbombte Häuser im Hintergrund einer ukrainischen Influencerin werden von der Software nicht als Solche erkannt.
Mit einer russischen Version des DALL-E Bildgenerators (ruDALL-E) und auf Basis der zuvor gesammelten algorithmischen Bildbeschreibungen entstehen “neue” künstliche Influencerinnen. Vorbild für ruDALL-E ist DALL-E von OpenAi und Microsoft, eine – wie oben bereits beschrieben – der ersten KI’s die aus kurzen Texten (Prompts) realistisch wirkende Bilder generiert. Die Differenzen zwischen westlichen und russischen Algorithmen und Trainingsdatenbanken werden hierbei also bewusst genutzt. Durch den zugehörigen Hashtag des originalen Videos wird ein direkter Bezug zwischen den sozialen Netzwerken und den generierten Bildern hergestellt. Das linke Bild zeigt das Standbild aus dem originalen TikTok-Video, das rechte Bild die aus den Labels generierte Influencerin.



Darf ich das?
Es stellt sich die in diesem Kontext entscheidende Frage, wie weit Kunst sich an Kriegsbildern bedienen darf, um gesellschaftliche Wirkkraft zu entfalten. Der Verfremdung der Kriegsbilder durch pop-kulturelle Ästhetik der Influencer*innen wird die gleichfalls verfremdende Ästhetik der KI-Algorithmen gegenübergestellt. Durch ästhetische Erfahrungen im Sinne einer Differenzerfahrung durch KI-generierte Bilder, appelliert somit das Projekt an unsere Selbstreflexion, um so, bestenfalls eine kritische Betrachtung unseres Umgangs mit den sozialen Netzwerken in Zeiten des Krieges zu ermöglichen.

ground zero Rückblick WiSe21/22 – SoSe 22
Seminare





Workshops






Shows / Exhibitions / Releases / Publications






Talks & Conferences


Artificial Intelligence as a weapon (FIfF) @ Living without NATO – ideas for peace



Software Releases

ground zero Vorschau WiSe 22/23
Seminare & Publikationen
Seminare



Publikationen
Workshops



Veranstaltungen (extern) Herbst/Winter ’22